触觉反馈对动态VR行人环境中用户避障行为与视觉探索的影响研究

当虚拟世界终于学会了“触摸”,我们与之互动的方式也将被彻底重塑
(映维网Nweon 2025年11月14日)在虚拟现实构建的宏大世界里,我们能用双眼见证奇迹,用双耳聆听共鸣,但我们的身体,却常常是沉默的。尤其是在模拟人群熙攘的街头或紧急疏散场景时,那份源于肌肤与肌肉的、对于拥挤和碰撞的微妙感知,一直处于缺失状态。这份缺失,使得我们在VR中的行为,与真实世界相比,总隔着一层难以言喻的疏离感。
针对这个问题,东京大学与斯坦福大学团队正尝试填补这一关键空白。他们的发现揭示:当虚拟世界能够“触摸”我们时,我们的身体会以更真实、更本能的方式作出回应。 这不仅是一项技术成就,更是我们理解人机交互、构建下一代沉浸式模拟器的重要一步。
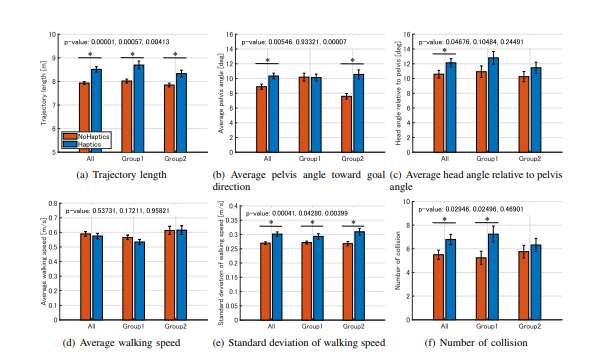
此前,学术界和产业界并非没有尝试在VR人群模拟中加入触觉反馈。然而,许多研究得出的结论颇为矛盾:有的认为触觉提升了沉浸感,但另一些,如Berton等人在2022年的研究,却发现它并未显著改变用户的行走路径。
......(全文 3421 字,剩余 3055 字)
 请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
映维网会员可直接登入网站阅读
PICO员工可联系映维网免费获取权限