香港科大提出因果强化学习新框架,显著提升多用户VR交互体验

在多用户虚拟现实交互中优化体验质量
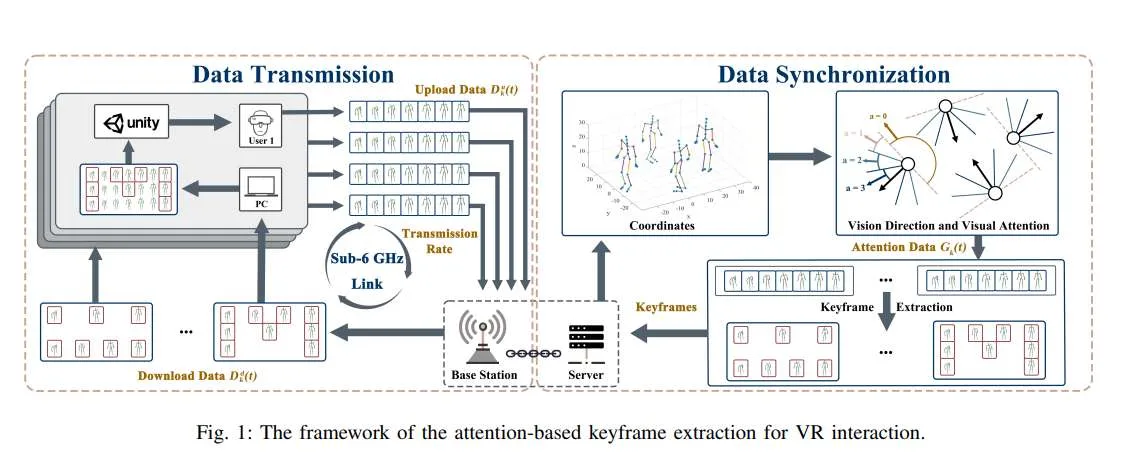
(映维网Nweon 2025年11月08日)在多用户虚拟现实交互中优化体验质量(QoE)需要在超低延迟、高精度运动同步与公平资源分配之间实现精妙平衡。尽管自适应关键帧提取技术能缓解传输开销,但现有方法往往忽视带宽分配、CPU频率与用户感知之间的因果关系,从而限制了QoE的提升。
在一项研究中,香港科技大学团队提出一种智能框架,通过将自适应关键帧提取与因果感知强化学习(RL)相结合来实现QoE最大化。首先基于韦伯-费希纳定律构建新型QoE度量指标,融合感知灵敏度、注意力驱动优先级和运动重建精度;随后将QoE优化问题建模为混合整数规划(MIP)任务,在水平公平约束下联合优化关键帧比率、带宽和计算资源。
团队提出部分状态因果深度确定性策略梯度(PS-CDDPG),将深度确定性策略梯度(DDPG)方法与因果影响检测相结合。通过利用关于QoE如何受各种动作影响并决定的因果信息,他们探索由因果推断(CI)计算权重引导的动作,从而提升训练效率。基于CMU运动捕捉数据库的实验表明,本框架显著降低交互延迟、提升QoE并保持公平性,相比基准方法实现更优性能。
......(全文 3543 字,剩余 3121 字)








