支持AR/VR等实时应用,印度团队介绍用于加速基于SfM的位姿估计的预处理技术

处理速度提升了1.5至14.48倍
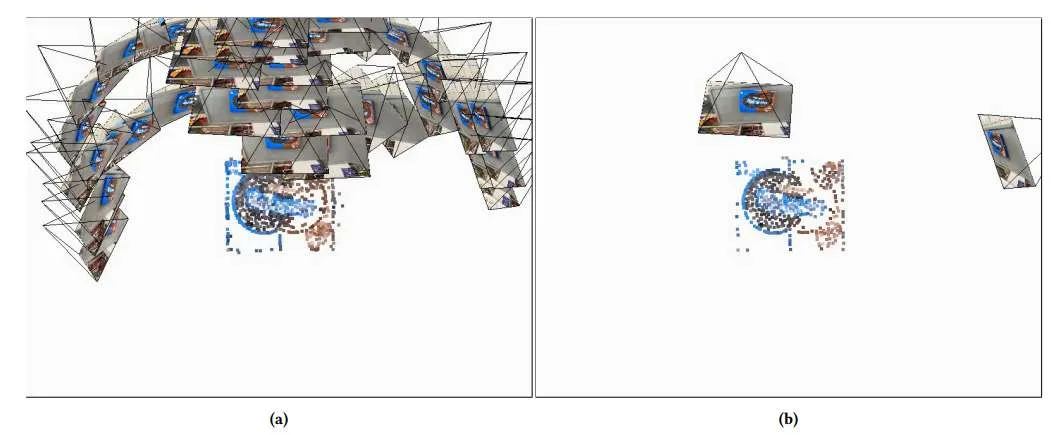
(映维网Nweon 2025年10月21日)在一项研究中,印度科学学院团队介绍了一种用于加速基于SfM的位姿估计的预处理技术,并可支持增强现实和虚拟现实等实时应用。所提出方法利用图论中的支配集概念对SfM模型进行预处理,在保持较高精度的同时显著提升了位姿估计的速度。
基于OnePose数据集,研究人员在多种SfM位姿估计技术上评估了本方法。实验结果表明:处理速度提升了1.5至14.48倍,参考图像数量和点云规模分别减少了17-23倍和2.27-4倍。这项研究为高效精准的3D位姿估计提供了创新解决方案,实现了实时应用中速度与精度的平衡。
新颖物体的精准位姿估计是计算机视觉领域的核心任务。这项任务需要精确识别物体的位置与朝向,对于准确操控物体或在增强现实的视频流中叠加虚拟对象至关重要。其核心挑战可简化为:给定物体的完整3D表征,如何精准定位其在图像中的位姿?
......(全文 2044 字,剩余 1709 字)








