摩根大通探索强化学习,让混合现实界面“随人而动”

在混合现实中实现个性化和优化的用户界面及内容放置
(映维网Nweon 2025年10月21日)混合现实能够通过将虚拟内容持续集成到用户对物理环境的视野中来辅助用户完成任务。然而,由于混合现实体验的动态特性,在何处以及如何放置这些内容以最好地支持用户一直是一个具有挑战性的问题。与之前基于优化方法的研究不同,摩根大通团队正在探索强化学习(RL) 如何能够辅助进行连续的、感知用户姿态及其周围环境的三维内容放置。
通过初步探索和评估,实验的结果展示了强化学习在为用户动态定位内容以最大化奖励方面的潜力。研究人员进一步指出了未来研究的方向,借助强化学习的力量,在混合现实中实现个性化和优化的用户界面及内容放置。
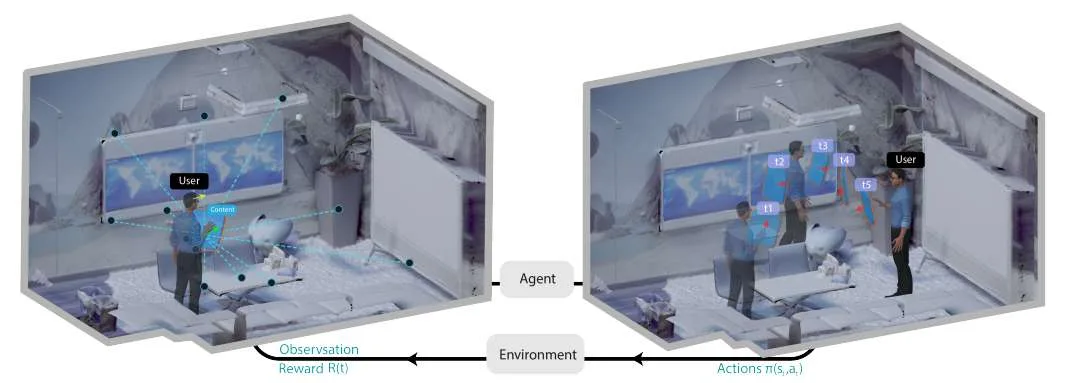
混合现实技术有潜力通过将数字内容普遍集成到用户对物理环境的视野中来辅助用户完成任务。用户得以在各种日常任务中移动过程中持续依赖这些数字信息。然而,由于混合现实用例自由度增加和动态变化的特性,确定三维用户界面在物理空间中的最佳位置提出了一个不小的挑战。
......(全文 3324 字,剩余 2921 字)








