清华大学与字节跳动团队提出参数化高斯人体模型PGHM

旨在从单目视频中进行快速且高保真的化身重建
(映维网Nweon 2025年10月20日)逼真且可动画化的人体化身是虚拟现实/增强现实的关键使能技术。尽管3DGS的最新进展极大地提升了渲染质量和效率,现有方法依然面临根本性挑战,包括耗时的逐主体优化以及在稀疏单目输入下的泛化能力差。
在一项研究中,清华大学和字节跳动团队提出了参数化高斯人体模型PGHM。这是一个可泛化且高效的框架,它将人体先验知识整合到3DGS中,旨在从单目视频中进行快速且高保真的化身重建。
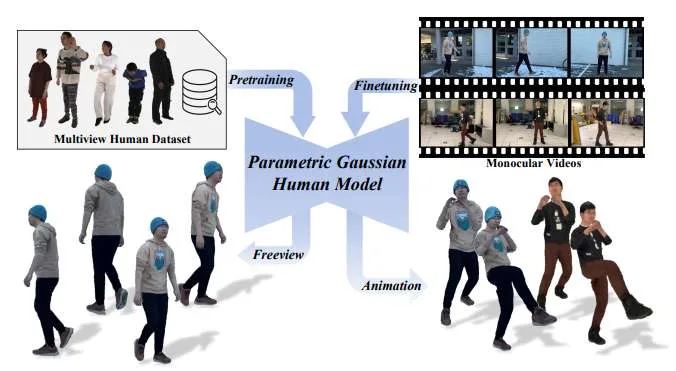
PGHM引入了两个核心组件:
(1) 一个UV-Aligned Latent Identity Map,它将特定主体的几何和外观紧凑地编码到一个可学习的特征张量中;
(2) 一个Disentangled Multi-Head U-Net,它通过条件解码器分解静态、姿态相关和视角相关的成分来预测高斯属性。
这种设计能够在具有挑战性的姿态和视角下实现鲁棒的渲染质量,同时允许高效的主体适应,而无需多视图捕获或漫长的优化时间。实验表明,PGHM比从零开始的优化方法效率显著更高,每个主体仅需约20分钟即可产生视觉质量相当的化身,从而证明了其在实际单目化身创建中的应用潜力。
......(全文 2792 字,剩余 2384 字)








