北京大学团队提出神经声学传输方法实现动态场景实时声音建模

能高效精确地建模动态变化环境中的声音行为
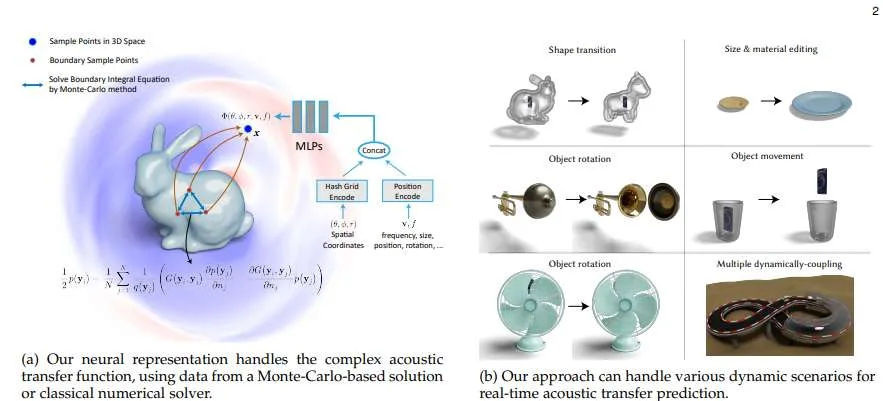
(映维网Nweon 2025年10月20日)先前的声音传输方法依赖于大量的预计算和数据存储来实现实时交互和听觉反馈。然而,相关方法难以处理复杂场景,特别是当物体位置、材料和尺寸的动态变化显著改变声音效果时。连续变化导致声学传输分布波动,难以用基本数据结构表示并实时高效渲染。为解决这一挑战,北京大学团队提出了Neural Acoustic Transfer神经声学传输,一种利用隐式神经表示对预计算声学传输及其变化进行编码的新方法,可实时预测不同条件下的声场。
为高效生成神经声场所需的训练数据,研究人员开发了基于蒙特卡洛的快速边界元法(BEM)近似算法,适用于满足光滑诺伊曼条件的通用场景。另外,实现了标准BEM的GPU加速版本用于高精度场景。所述方法提供了必要的训练数据,可支持神经网络精确建模声音辐射空间。通过在不同声学传输场景中的全面验证与对比,证明了所述方法具备数值精确性和运行效率(30秒音频处理仅需数毫秒)。
北京大学团队指出,所提出方案能高效精确地建模动态变化环境中的声音行为,可广泛应用于虚拟现实和增强现实等交互场景。
......(全文 2608 字,剩余 2179 字)








