清华大学提出OGGSplat实现稀疏视图语义感知3D场景重建视场扩展

语义感知场景重建
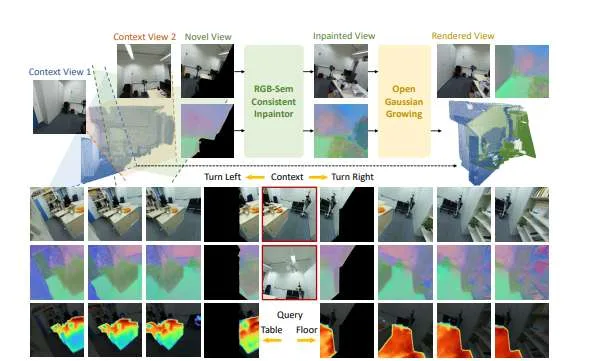
(映维网Nweon 2025年10月16日)基于虚拟现实等新兴应用的需求,从稀疏视图重建语义感知的3D场景成为一个具有挑战性但至关重要的研究方向。现有的逐场景优化方法需要密集的输入视图且计算成本高昂,而通用化方法往往难以重建输入视锥范围之外的区域。在一向研究中,清华大学团队提出了OGGSplat,一种通过开放高斯生长实现通用化3D重建视场扩展的方法。
研究人员的核心洞察是:开放高斯的语义属性为图像外推提供了强先验,既能保证语义一致性又能保持视觉合理性。具体而言,在从稀疏视图初始化开放高斯后,引入应用于选定渲染视图的RGB-语义一致性修复模块。
所述模块通过图像扩散模型与语义扩散模型实现双向控制,随后将修复区域投影回3D空间进行高效渐进的高斯参数优化。为评估方法性能,团队建立了高斯外推基准测试,从语义质量和生成质量两个维度评估重建的开放词汇场景。即使直接使用智能手机拍摄的两张视图图像,OGGSplat都展现出优秀的语义感知场景重建能力。
......(全文 2528 字,剩余 2143 字)








