AsynFusion框架实现高效全身音频驱动虚拟化身动画生成

AsynFusion在生成实时、同步的全身动画方面达到了最先进的性能,在定量和定性评估中均持续优于现有方法
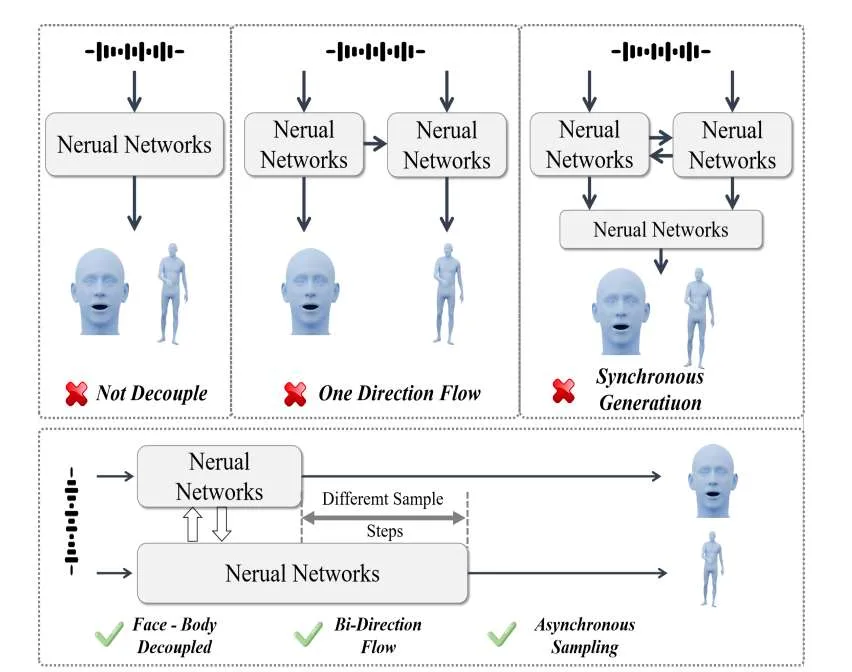
(映维网Nweon 2025年09月12日)全身音频驱动虚拟化身姿态与表情生成是创造逼真数字人、增强交互式虚拟代理能力的关键任务,在虚拟现实和远程通信中具有广泛应用。现有方法通常独立生成音频驱动的面部表情和身体姿态,这带来了一个显著限制:面部表情与身体姿态元素之间缺乏无缝协调,导致生成的动画不够自然和连贯。
为克服这一限制,北京航空航天大学,上海交通大学,中国电信人工智能研究院和GigaAI团队提出了 AsynFusion,一种利用DiT实现和谐表情与姿态合成的新型框架。
所提出方法基于双分支DiT架构构建,支持面部表情与身体姿态的并行生成。在模型内部,引入协同同步模块以促进两种模态之间的双向特征交互,以及一种异步LCM采样策略,在保持高质量输出的同时降低计算开销。大量实验表明,AsynFusion在生成实时、同步的全身动画方面达到了最先进的性能,在定量和定性评估中均持续优于现有方法。
......(全文 2957 字,剩余 2573 字)








