北卡罗来纳大学团队提出运动感知CLIP优化模型MoCLIP

改善了文本到运动的对齐结果
(映维网Nweon 2025年09月05日)人体运动生成对于虚拟现实等领域至关重要,这要求模型能够有效地从文本描述中捕获运动动态。现有方法通常依赖于基于对比语言-图像预训练(CLIP)的文本编码器,但模型在文本-图像对上的训练限制了它们理解运动及运动生成固有的时间和运动学结构的能力。
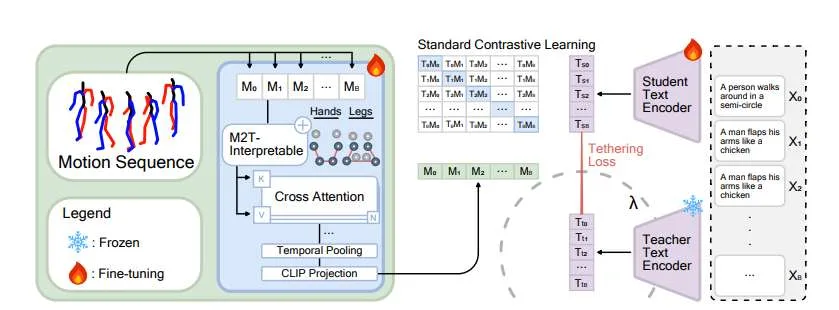
在一项研究中,北卡罗来纳大学夏洛特分校团队提出了 MoCLIP,这是一个经过微调的 CLIP 模型,增加了一个运动编码头。模型通过对比学习和束缚损失在运动序列进行训练。通过显式地融入运动感知的表征,MoCLIP 在保持与现有基于 CLIP 的流程兼容性的同时,增强了运动保真度,并能无缝集成到各种基于 CLIP 的方法中。
实验表明,MoCLIP 在保持竞争力强的 FID(弗雷歇起始距离)的同时,提高了 Top-1、Top-2 和 Top-3 检索准确率,从而改善了文本到运动的对齐结果。相关结果突显了 MoCLIP 的通用性和有效性,将其确立为一个增强运动生成的鲁棒框架。
......(全文 3280 字,剩余 2927 字)








