意大利研究团队提出基于人眼感知的自适应超分辨率优化方法

将计算努力集中在注视点视觉区域能带来显著的计算节省
(映维网Nweon 2025年09月05日)超分辨率(SR)技术对于在较低带宽下传输高质量内容以及满足虚拟现实和增强现实中的现代显示需求至关重要。遗憾的是,当前最先进的神经网络超分辨率方法计算成本依然高昂。意大利提契诺大学团队认为,可以利用人类视觉系统(HVS)的局限性,有选择性地分配计算资源,即通过低层次感知模型识别出感知上重要的图像区域,并采用计算要求更高的超分辨率方法进行处理,而对重要性较低的区域则使用更简单的方法。
这种方法的灵感来源于内容感知注视点渲染技术 ,它能在不牺牲感知视觉质量的前提下优化效率。用户研究和定量结果表明,团队提出的方法在计算需求上实现了显著降低,且没有可察觉的质量损失。所述技术与具体架构无关,非常适合VR/AR应用,因为将计算努力集中在注视点视觉区域能带来显著的计算节省。
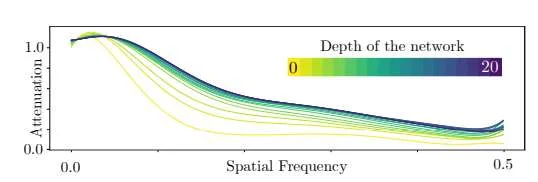
研究人员提出的方法基于两个关键观点。首先,他们注意到神经超分辨率方法在重建高空间频率信息方面的能力取决于模型的复杂性和规模。通过创建超分辨率模型的简化版本,团队得到了更高效的解决方案,但代价是其无法重建高频内容。他们利用在图像数据集上测量得到的衰减曲线(代表不同模型重建不同空间频率的能力,见图2),为特定的一组CNN模型量化了这些权衡关系。
......(全文 1735 字,剩余 1228 字)








