上海交大与电子科大团队提出轻量级单目深度估计算法LMDepth

单目深度估计
(映维网Nweon 2025年08月25日)单目深度估计旨在从单张RGB图像预测深度图,并在一系列的领域中存在重要作用,例如AR。目前已有大量基于卷积神经网络和Transformer的单目深度估计方法,并取得了显著成果。然而,大多数现有方法主要侧重于提高精度,往往忽视了在资源受限设备部署的挑战。
为解决这一问题,当前的轻量级单目深度估计方法主要采用基于CNN的架构以降低计算复杂度。但由于CNN感受野大小固定,模型在优化过程中更容易陷入局部最优。相比之下,基于Transformer的架构利用全局注意力机制捕获更广阔的视野,解决了CNN在建模全局上下文方面的局限,但其二次方的计算成本给轻量化实现带来了巨大挑战。因此,探索更高效的轻量级网络架构以平衡性能和计算开销至关重要。图2(a)和2(b)分别简要展示了CNN和Transformer的计算流程。
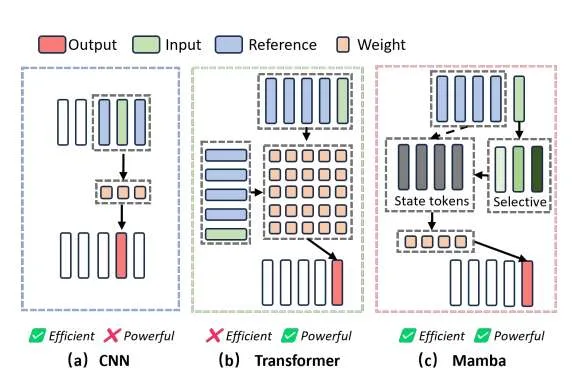
近期,基于Mamba的网络架构在图像分类、检测和分割等多种视觉任务上显著推动了状态空间模的研究。作为一种新兴框架,Mamba在SSM中融入了两项关键改进:首先,Mamba引入了一种输入依赖机制,能够动态调整状态空间模型(SSM)的参数。
......(全文 2220 字,剩余 1814 字)








