上海交通大学发布AI生成3D人脸质量评估数据集Gen3DHF

评估AI生成3D人脸的质量
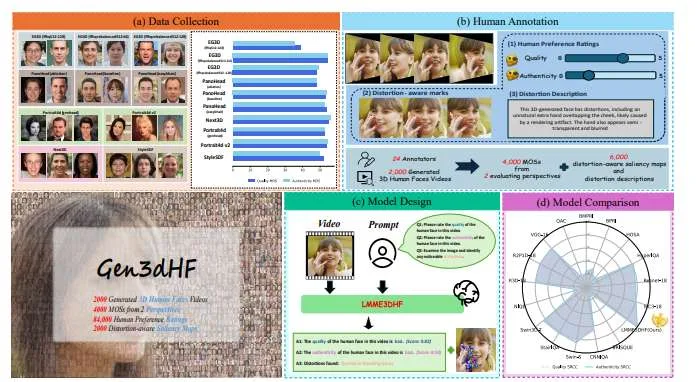
(映维网Nweon 2025年08月15日)生成式人工智能的快速发展使得创建3D人脸成为可能,并可为虚拟现实等领域带来帮助。然而,由于人类感知的主观性以及对面部特征固有的感知敏感性,评估AI生成3D人脸的质量和真实感依然是一项重大挑战。所以,上海交通大学团队开展了一项关于AI生成3D人脸质量评估的综合研究。
团队首先介绍了Gen3DHF,这是一个大规模基准数据集,包含2000个AI生成的3D人脸视频,以及从质量和真实感两个维度收集的4000个平均意见得分(MOS)、2000个失真感知显著图和失真描述。基于Gen3DHF,团队进一步提出了LMME3DHF,这是一个基于大型多模态模型LMM的3DHF评估指标,能够进行质量和真实感得分预测、失真感知视觉问答(VQA)以及失真感知显著性预测。
实验结果表明,LMME3DHF在准确预测AI生成3D人脸的质量得分、有效识别失真感知显著区域和失真类型方面均取得了最先进的性能,超越了现有方法,同时与人类感知判断保持了高度一致。
......(全文 2504 字,剩余 2153 字)








