德国团队开发大语言模型VR触觉反馈系统Scene2Hap

自动为整个VR场景设计物体级振动触觉反馈
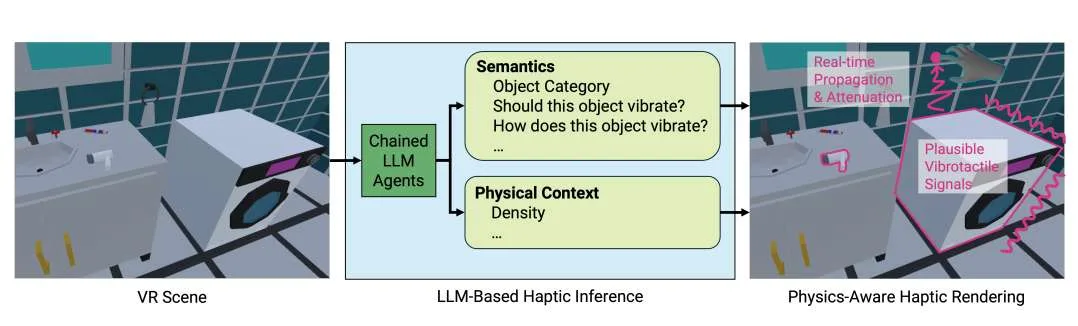
(映维网Nweon 2025年08月14日)触觉反馈有助于创造沉浸式的虚拟现实体验。然而,为VR场景中的所有物体及其各自排列设计这种反馈,依然是一项耗时的工作。在一项研究中,德国萨尔大学和马克斯·普朗克信息学研究所团队提出了Scene2Hap。这是一个以大语言模型LLM为核心的系统,能够基于物体的语义属性和物理上下文,自动为整个VR场景设计物体级振动触觉反馈。
Scene2Hap采用多模态大语言模型,根据VR场景中的多模态信息,估算每个物体的语义和物理上下文,包括其材质属性和振动行为。然后,利用相关语义和物理上下文,通过生成或检索音频信号并将其转换为振动触觉信号,来创建可信的振动触觉信号。为了在VR中实现更逼真的触觉空间渲染,Scene2Hap考虑估算的材质属性(如密度)和物理上下文(如虚拟物体之间的距离和接触关系),计算振动信号从源头在场景中物体间的传播和衰减。
两项用户研究的结果证实,Scene2Hap能成功估算VR场景的语义和物理上下文,并且振动物理传播建模提高了可用性、材质感知度和空间感知能力。
......(全文 2650 字,剩余 2248 字)








