德国研究团队提出CNN方法改进VR眼动追踪距离估计

估计注视距离
(映维网Nweon 2025年08月11日)虚拟现实中的眼动追踪技术可以提高真实感和沉浸感。知道被注视对象的距离,而不仅仅是注视方向,是至关重要的。一种常用的方法是估计视线距离,即两眼之间的相对角度,但这种方法的准确性有限,特别是对于较大的距离。或者,VR中的注视距离可以直接从估计注视点的深度图中检索。然而,眼动追踪的不准确性可能导致被测量的注视指向不正确的对象,从而导致错误的距离估计。这个问题尤其在盯着小目标或物体边缘时发生。
为了解决这个问题,德国图宾根大学团队引入了一种基于CNN的方法,将深度图数据与眼动追踪的收敛信息相结合。实验表明,模型成功地学会了结合来自两个特征的信息,并且优于最先进的方法。
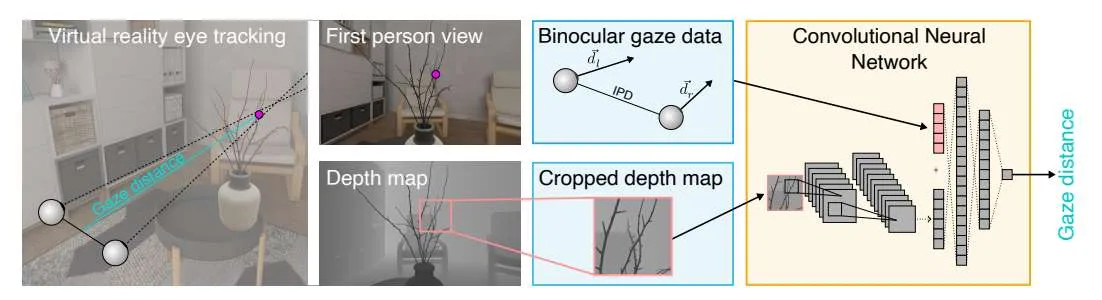
虚拟现实系统通常以固定的光学距离呈现图像,导致感知图像缺乏自然的深场模糊。用户的眼睛必须聚焦在这个固定的光学距离上,而双眼之间的角度必须与虚拟环境中固定物体的距离相匹配。这种不匹配通常称为视觉辐辏调节冲突(VAC),并且是VR中一个众所周知的问题,会导致视觉不适和疲劳。
......(全文 2685 字,剩余 2276 字)