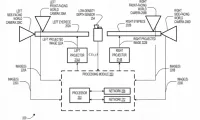
德国研究团队开发神经自适应触觉系统以优化XR体验

一个集成实时神经和生理数据的交互系统,以动态地修改虚拟,增强或混合环境中的触觉
(映维网Nweon 2025年07月31日)神经自适应触觉通过动态调整用户偏好的多感官反馈,为XR体验提供了一条增强沉浸感的途径。在一项研究中,德国柏林工业大学和勃兰登堡工业大学团队提出了一种神经自适应触觉系统,通过强化学习(RL)从显式用户评分和大脑解码的神经信号中适应XR反馈。
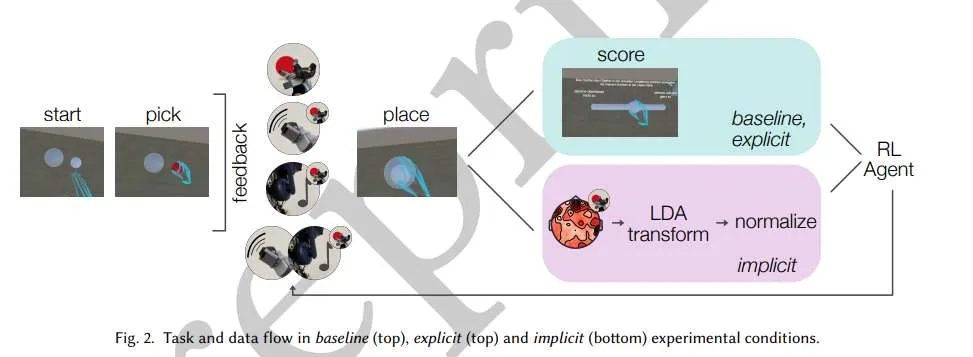
在一项用户研究中,参与者与虚拟现实中的虚拟对象进行互动,同时记录脑电图(EEG)数据。RL代理根据显式评分或神经解码器的输出调整触觉反馈。结果表明,RL智能体的表现在不同的反馈源之间具有可比性,这表明内隐神经反馈可以在不需要用户主动输入的情况下有效地指导个性化。基于脑电图的神经解码器平均F1得分为0.8,支持可靠的用户体验分类。这些发现证明了将脑机接口(BCI)和RL结合起来自主适应XR交互,减少认知负荷和增强沉浸感的可行性。
XR有可能创造出深刻的沉浸式体验。然而,实现最佳体验需要微调各种设置,从亮度和视场到触觉反馈和空间音频。目前,用户通过与传统桌面环境非常相似的传统菜单界面手动调整参数,但这带来了巨大的摩擦。频繁的干扰,特别是初始设置,会破坏沉浸感,降低兴奋感,并可能降低长期采用率。
......(全文 3141 字,剩余 2667 字)