马克斯·普朗克研究所与谷歌联合开发稀疏视图人体化身生成技术

在跨对象泛化能力和逼真度方面,所提出方法显著优于先前的研究。
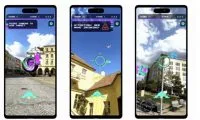
(映维网Nweon 2025年07月24日)仅靠少数数个RGB摄像头就能制造出高质量、逼真的人体化身,这是一个具有挑战性的问题,并且随着虚拟现实技术的兴起变得越来越重要。为了帮助这种技术实现普及,一种富有前景的解决方案可能是一种可泛化方法,即获取目标人物的稀疏多视图图像,然后生成真实自由视图渲染图。
然而,目前的技术水平尚不能扩展到非常大的数据集,所以缺乏多样性和真实感。为了解决这个问题,马克斯·普朗克信息学研究所,马普所萨尔布吕肯视觉计算研究中心,以及谷歌团队提出了一种全新的、可泛化的全身模型,以稀疏多视角视频作为驱动信号,它可以在自由视点下渲染逼真人体。模型在维持高逼真度的同时,可以将训练扩展到数千个研究对象。
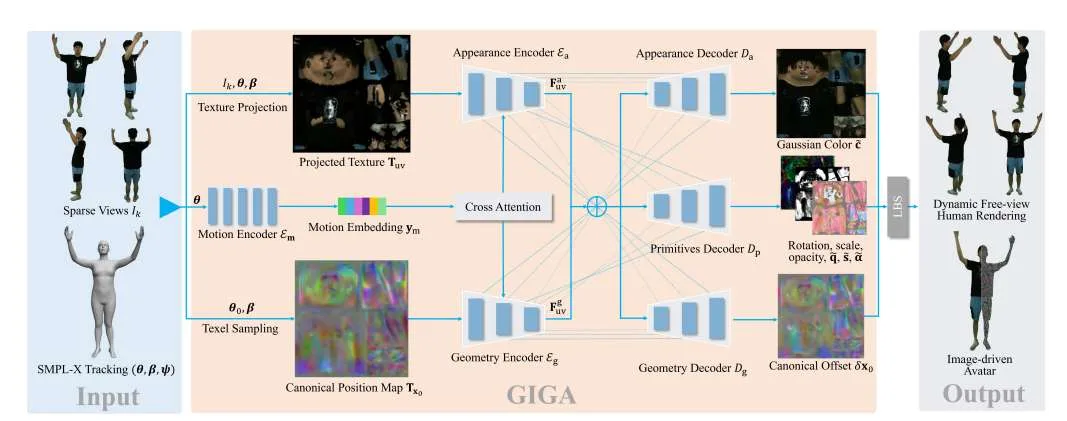
就其核心,研究人员引入了一个MultiHeadUNet架构,它以纹理空间中的稀疏多视图图像作为输入,并预测在人体网格表示为二维纹理的高斯基元。重要的是,在2D中表示稀疏视图图像信息,身体形状和高斯参数,以便可以完全基于2D卷积和注意力机制设计一个深度和可扩展的架构。在测试时,仅需四路输入视图以及一个针对目标身份的跟踪身体模板,即可合成出基于高斯分布的关节式3D Avatar。在跨对象泛化能力和逼真度方面,所提出方法显著优于先前的研究。
......(全文 2835 字,剩余 2339 字)