中外四所高校联合提出虚拟现实模块化图像合成新方法

条件图像合成
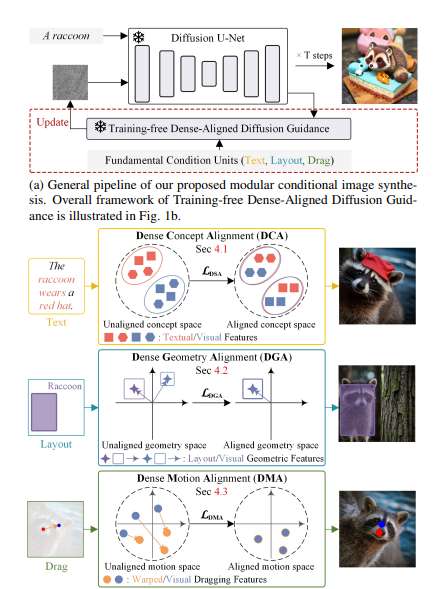
(映维网Nweon 2025年07月14日)条件图像合成是一项具有广泛应用的关键任务,例如虚拟现实。然而,目前的生成方法往往是面向任务的,范围狭窄,处理的是有限的条件,适用性有限。在一项研究中,四川大学,新加坡科技设计大学,阿德莱德大学和澳大利亚国立大学团队提出了一种新的方法,将条件图像合成作为多种基本条件单元的模块化组合。
具体来说,将条件分为三个主要单元:文本、布局和拖动。为了有效控制条件,研究人员为每个条件设计了专用的校准模块。针对文本条件,引入了密集概念对齐(DCA)模块,通过绘制不同的文本概念来实现密集的视觉文本对齐。对于布局条件,密集几何对齐(DGA)模块用于强制执行保留空间配置的综合几何约束。对于拖动条件,密集运动对齐(DMA)模块应用多级运动正则化,确保每个像素遵循其所需的轨迹而不会产生视觉伪影。
通过灵活地插入和组合对齐模块,相关方法增强了模型对各种条件生成任务的适应性,极大地扩展了模型的应用范围。大量的实验证明了框架在各种条件下的卓越性能,包括文本描述、分割掩码、拖动操作及其组合。
......(全文 1652 字,剩余 1237 字)
 请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
映维网会员可直接登入网站阅读
PICO员工可联系映维网免费获取权限







