佐治亚理工学院研发边缘GPU高斯混合单元提升AR/VR渲染性能

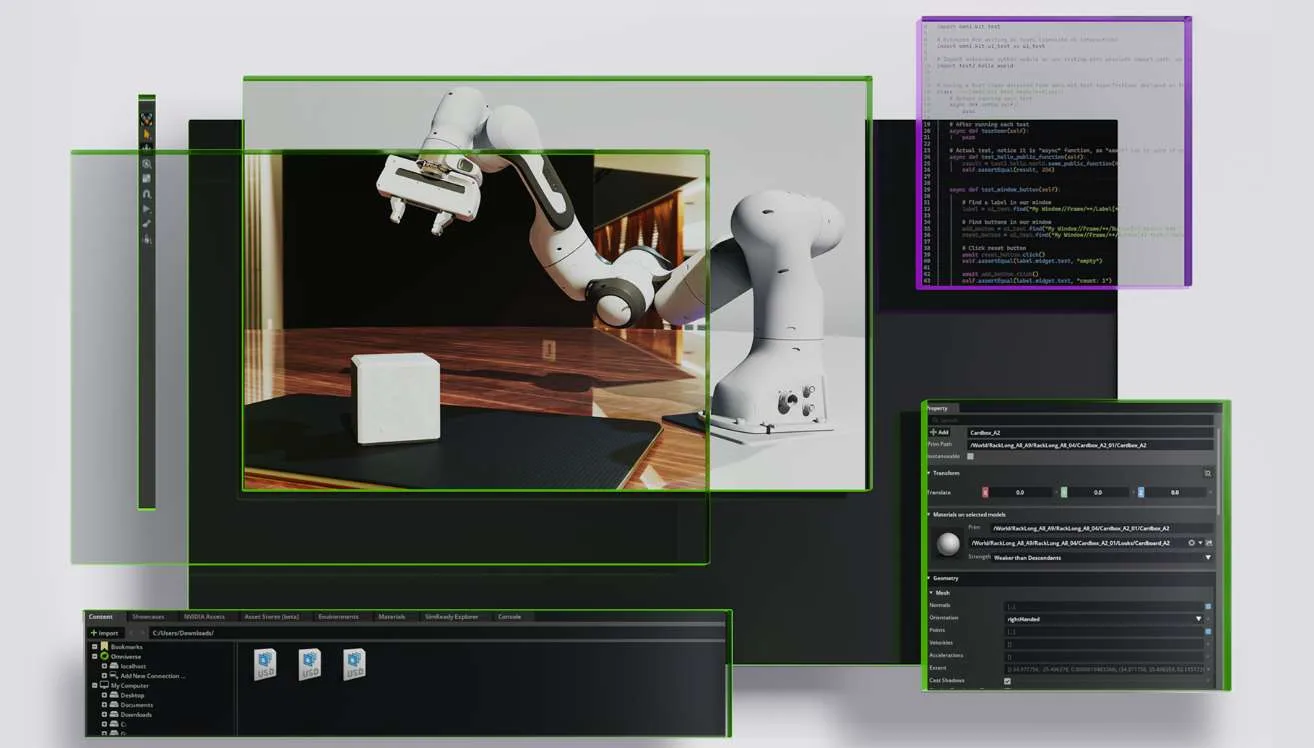
一个边缘GPU插件模块
(映维网Nweon 2025年07月11日)快速发展的增强现实和虚拟现实要求在资源受限的平台进行实时、逼真的渲染。3D高斯飞溅在渲染效率和质量方面提供了最先进的(SOTA)性能,并已成为广泛的AR/VR应用中有前途的解决方案之一。然而,尽管它在高端GPU表现出色,但在边缘系统却举步维艰,每秒帧数仅为7-17帧,远低于真正沉浸式AR/VR体验所需的60帧以上标准。
为了解决这一挑战,佐治亚理工学院团队对基于高斯的AR/VR应用进行了全面分析,并确定了高斯混合阶段(集中计算每个高斯在每个像素的贡献)作为主要瓶颈。为此,他们提出了一个高斯混合单元(GBU),一个边缘GPU插件模块,以用于AR/VR应用的实时渲染。
值得注意的是,这个GBU可以无缝集成到传统的边缘GPU中,并协同支持广泛的AR/VR应用。具体来说,GBU结合了行内顺序着色(IRSS)数据流,利用两步坐标变换,从左到右依次遮蔽每一行像素。当直接部署在GPU时,所提出的数据流在真实的静态场景中实现了1.72倍的加速(但依然缺乏实时渲染性能)。
考虑到基于GPU的实现中有限的计算利用率,GBU使用专用的渲染引擎来提高渲染速度,通过聚合来自多个高斯的计算来平衡跨行工作负载。跨代表性AR/VR应用的实验表明,GBU在保持SOTA渲染质量的同时,为设备的实时渲染提供了一个解决方案。
......(全文 2392 字,剩余 1914 字)