密歇根大学团队提出SAM引导的3D语义分割跨域自适应方法

所提出方法显著增加了高质量伪标签的数量,并且比基线方法提高了自适应性能
(映维网Nweon 2025年05月29日)多模态3D语义分割对于虚拟现实等应用至关重要。为了在现实场景中有效地部署模型,必须采用跨领域适应技术,以弥合训练数据和现实数据之间的差距。近年来,基于伪标签的自训练方法已成为多模态三维语义分割中跨域自适应的主要方法。然而,生成可靠的伪标签需要严格的约束,这通常会导致修剪后的伪标签稀疏,而这种稀疏性可能会在适应过程中阻碍性能改进。
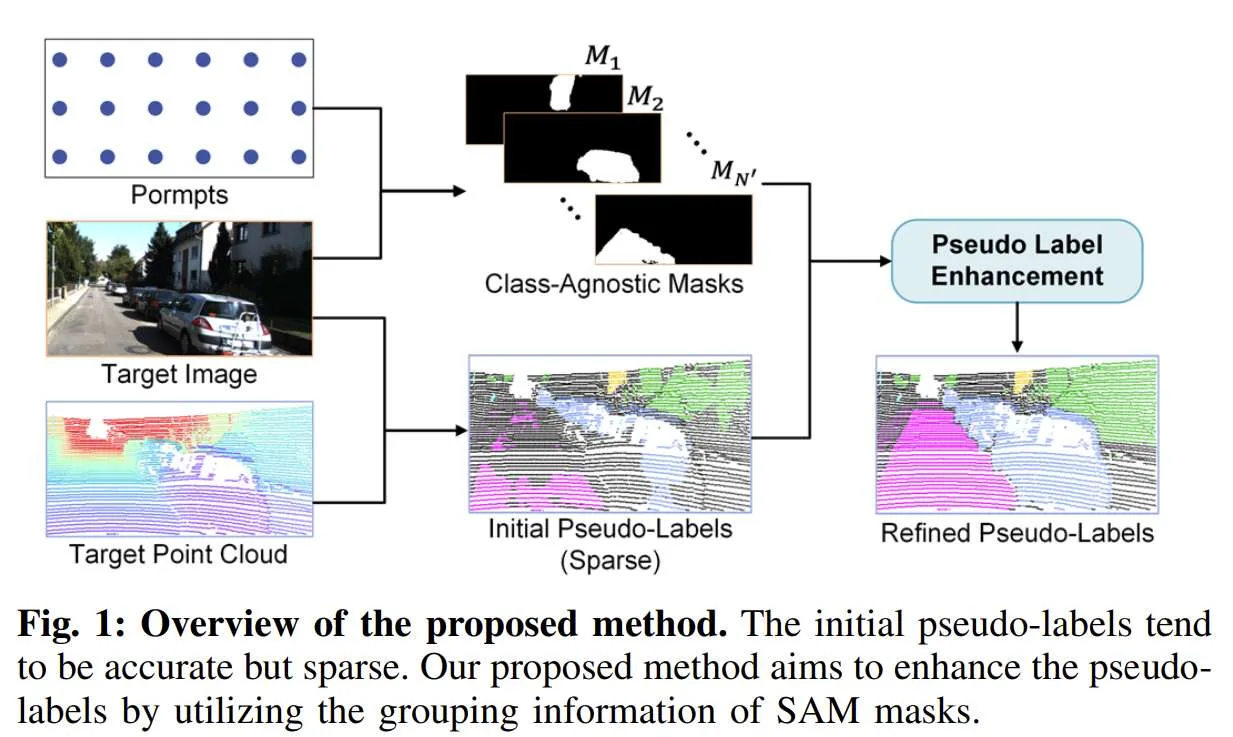
在一项研究中,密歇根大学团队提出了一种图像引导的伪标签增强方法。利用来自Segment Anything Model(SAM)的互补2D先验知识引入更可靠的伪标签,从而提高域自适应性能。
具体来说,给定一个3D点云和配对图像数据中的SAM掩码,收集每个SAM掩码覆盖的所有可能属于同一对象的3D点。然后,分两步对每个SAM掩码中的伪标签进行细化。首先,使用多数投票确定每个掩码的类标签,并使用各种约束来过滤掉不可靠的掩码标签。
接下来,引入几何感知渐进传播GAPP,将掩码标签传播到SAM掩码内的所有3D点,同时避免了2D-3D不对齐造成的异常值。
跨多个数据集和领域自适应场景的实验表明,所提出方法显著增加了高质量伪标签的数量,并且比基线方法提高了自适应性能。
近年来,3D语义分割已成为3D场景理解中的关键任务,对于增强现实/虚拟现实等应用至关重要。在全新多模态数据集的推动下,图像数据集成越来越多地用于提高3D语义分割的准确性,因为它提供了丰富的纹理和颜色细节等互补的2D信息,补充了3D点云的几何信息。
......(全文 1485 字,剩余 910 字)








