中国团队为R/VR大模型内容生成发布500万组EgoVid-5M数据集

数据集
(映维网Nweon 2025年04月15日)视频生成已经成为世界模拟的一个重要工具,可以利用视觉数据来复制现实世界的环境。以人类视角为中心的以自中心视频生成在增强虚拟现实和增强现实等应用方面具有巨大的潜力。
然而,由于自中心视点的动态性、行为的复杂性和所遇场景的复杂性,自中心视频生成面临着巨大的挑战,现有的数据集不足以有效应对。
为了弥补这一差距,阿里巴巴,中国科学院自动化研究所,清华大学和中国科学院大学团队提出了一个相关的数据集EgoVid-5M。
它包含500万个自中心视频剪辑,并提供了详细的动作注释。为了确保数据集的完整性和可用性,团队实现了一个复杂的数据清洗管道,目标是保持帧一致性、动作一致性和自中心条件下的运动平滑性。
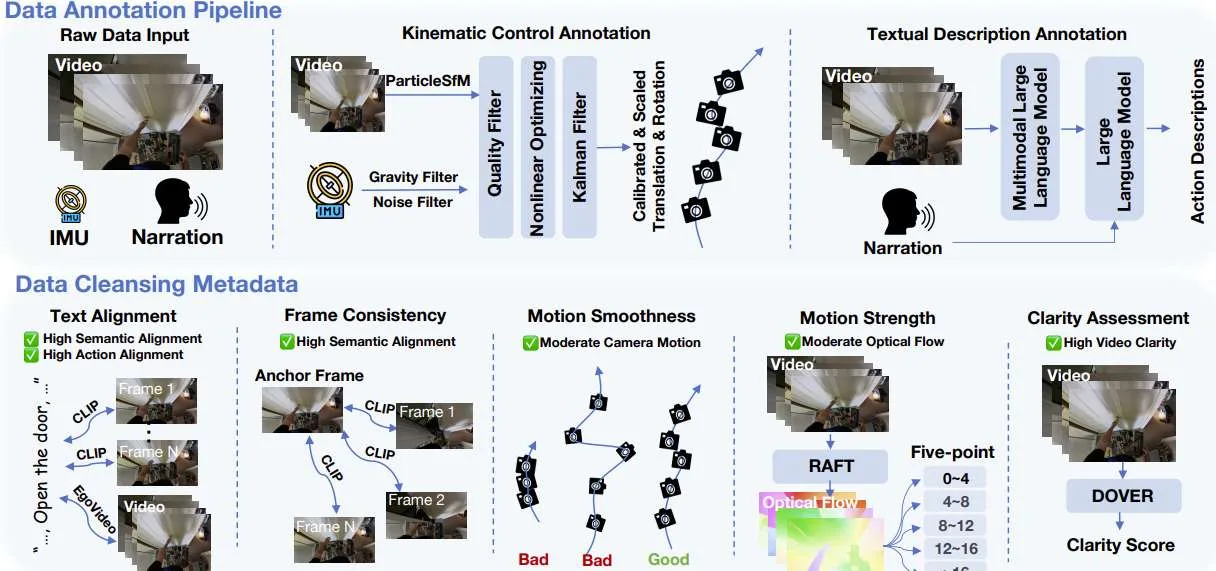
在视频生成领域,世界模拟器的开发十分重要。相关系统利用视觉模拟和交互在物理世界中提供应用程序。当代研究越来越多地验证了视频生成在这一领域的能力,包括AR/VR。
......(全文 1336 字,剩余 976 字)











