如何提升AR/VR深度图重建技术:Depth Upsampling Challenge大赛方案分享

汇总简介了排名前列的方法
(映维网Nweon 2025年02月27日)AR/VR日益增长的需求凸显了对高效深度信息处理的需求。深度图对于渲染逼真的场景和支持高级功能至关重要,但由于其大小,深度图通常很大且具有挑战性。深度压缩通常会降低质量,丢失场景细节并引入伪影。通过对深度上采样方法的改进,可以提高深度图重建的效率和质量。
所以AIM 2024 ECCV有一个Depth Upsampling Challenge大赛,而一系列的团队均提出了自己的解决方案。在下文中,由赛事赞助方德国维尔茨堡大学,索尼,Meta等组成的团队汇总简介了排名前列的作品,并希望可以鼓励开发新的深度上采样技术,以实现效率和深度图质量之间的平衡,从而帮助推进最先进的深度处理技术,并增强AR和VR应用的整体用户体验。
给定HR RGB图像和压缩后的LR深度图,所提出的方法必须重建HR深度图。表1提供了挑战赛的基准,其中包括以mac为单位测量的计算复杂性,以及每个模型的参数数量。
◐ 团队UM-IT:A Simple and Effective Baseline for Depth Upsampling and Refinement
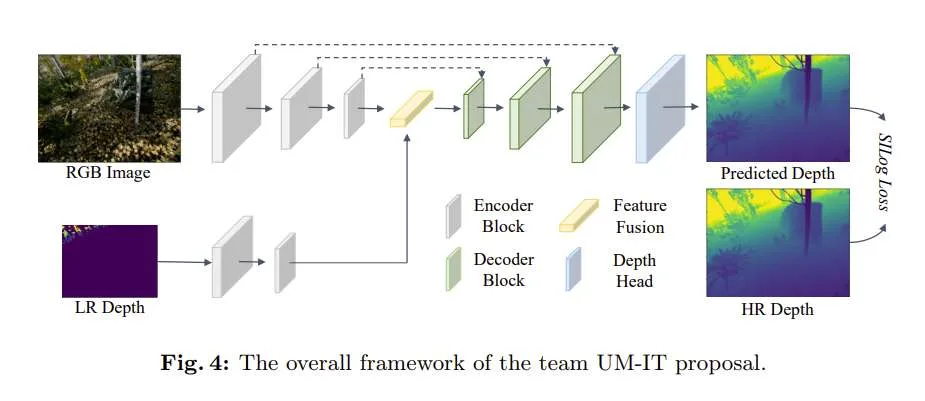
......(全文 2507 字,剩余 2143 字)










