Bang & Olufsen提出基于对比学习的房间声学盲估计与生成方法

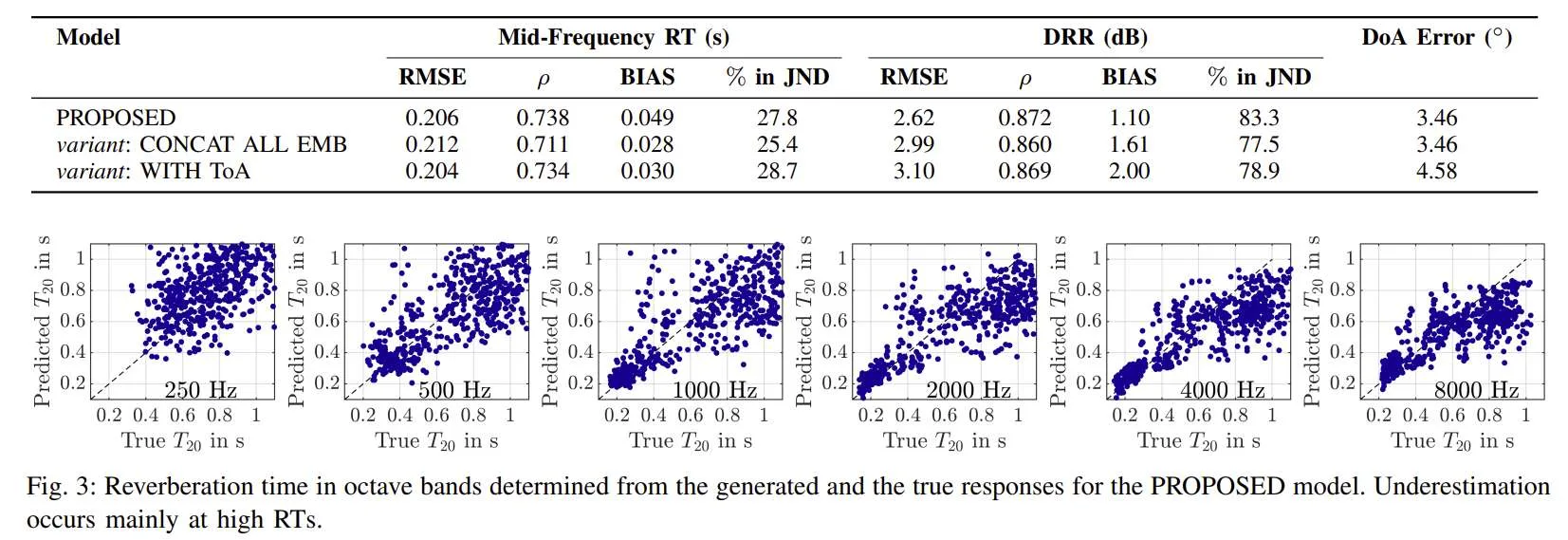
实验强调了这种方法在感知方面的可行性
(映维网Nweon 2025年02月25日)对于AR中的音频,理解用户的真实声学环境对于呈现无缝融入环境的虚拟声音至关重要。由于声学测量在实际的AR应用中通常不可行,所以需要从可用的声源中推断房间的信息。然后,可以用相同的房间声学质量渲染额外的声源。至关重要的是,它们放置在不同的位置,而不是说可用的估计源。
对于这一点,Bang & Olufsen和芬兰阿尔托大学团队建议使用通过对比损失训练的编码器网络,将输入声音映射到仅表示房间特定信息的低维特征空间。然后,训练一个基于扩散的空间房间脉冲响应发生器,在给定新的源-接收位置时,利用latent空间产生新的响应。
对于AR远程呈现,声学的基本任务是渲染虚拟声源,无缝集成到真实的声学场景。要做到这一点,虚拟声源必须以双耳方式呈现,并结合用户房间的声学环境。由于不可能对每个用户的声环境进行专门的测量,所以必须根据真实场景中的音频信号盲估房间声学。所以,盲估感知有效的空间房间脉冲响应(SRIRs)最为重要,它包含了在给定房间中特定源和听者位置呈现虚拟源的时间和方向信息。
......(全文 1663 字,剩余 1240 字)








