浙江大学和雷鸟团队提出一种高效的视觉定位方法SplatLoc

高效的视觉定位方法
(映维网Nweon 2025年02月25日)视觉定位在AR中起着重要的作用,它允许AR设备在预构建地图中获得六自由度的姿态,从而在真实场景中渲染虚拟内容。然而,大多数现有方法不能实现新视图渲染,并且需要大量的存储容量。
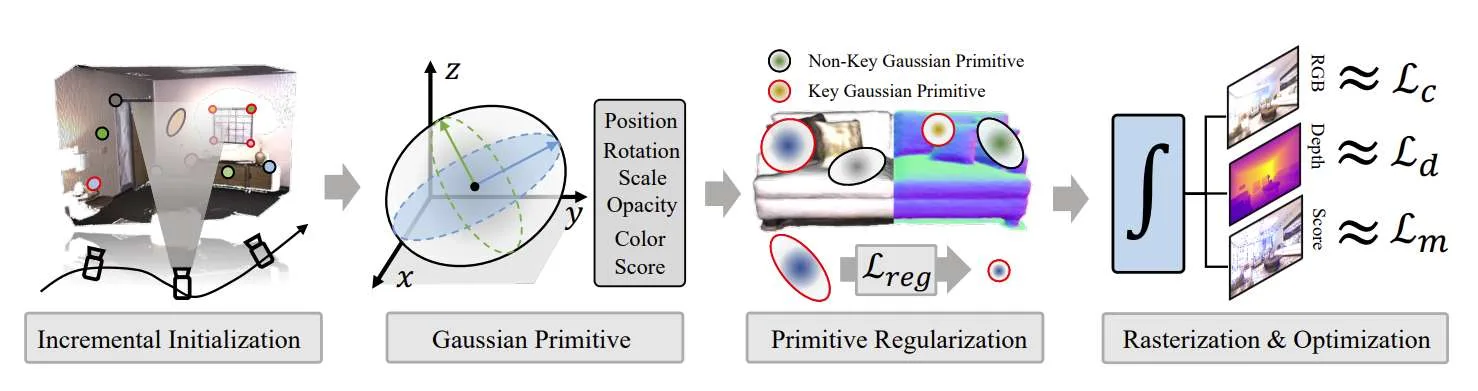
为了克服所述限制,浙江大学和RayNeo雷鸟团队提出了一种高效的视觉定位方法,能够用更少的参数实现高质量的渲染。具体来说,相关方案利用3D高斯原语作为场景表示。为了确保姿态估计的精确2D-3D对应,他们为高斯原语开发了一个无偏3D场景特定描述符解码器。
另外,研究人员引入了一种显著性3D Landmark选择算法,根据显著性评分选择合适的原语子集进行定位。他们进一步正则化关键高斯原语以防止各向异性效应,这同时提高了定位性能。在两个广泛使用的数据集进行的大量实验表明,所述方法与最先进的隐式视觉定位方法相比,具有优越或相当的渲染和定位性能。
......(全文 1629 字,剩余 1289 字)








