腾讯提出基于深度学习的空间音频Ambisonic编码方法

更好的音色和空间质量以及更高的源定位精度
(映维网Nweon 2025年02月18日)普林斯顿大学和腾讯团队认为,像Ambisonics这样的空间音频格式非常适合于虚拟现实等应用。传统的Ambisonic编码方法通常依赖于球形麦克风阵列来实现有效的声场捕获,而这限制了它们在实际场景中的灵活性。
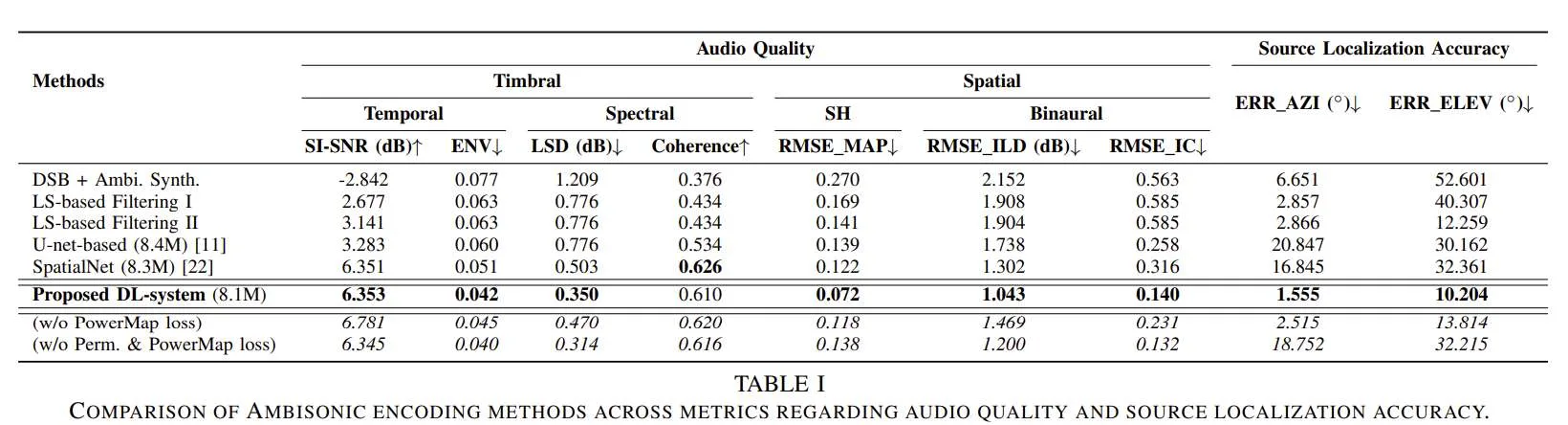
针对所述问题,研究人员提出了一种基于深度学习的方法,利用两阶段网络架构将圆形麦克风阵列信号编码为多扬声器环境中的Second-Order Ambisonic(SOA)。另外,他们通过一种基于空间功率映射的新型损失函数来正则化Ambisonic信号的信道间相关性,以及一种信道置换技术来解决使用水平圆形阵列编码垂直信息的模糊性。
对模拟语音和噪声数据集的评估表明,所述方法始终优于传统的信号处理(SP)和基于深度学习的方法,提供了更好的音色和空间质量以及更高的源定位精度。
......(全文 1481 字,剩余 1166 字)