英国团队推出适用于XR应用的单目深度学习框架NimbleD

对于需要低延迟推理的虚拟现实和增强现实应用特别有益
(映维网Nweon 2025年02月11日)在一项研究中,英国雷丁大学团队介绍了一个有效的自监督单目深度估计学习框架NimbleD。它结合了由大视觉模型生成的伪标签的监督,不需要camera内参,可在公开可用的视频进行大规模的预训练。
团队指出:“这个简单而有效的学习策略显著提高了快速和轻量级模型的性能,不会引入任何开销,使得它们能够达到与最先进的自监督单目深度估计模型相当的性能。这一进步对于需要低延迟推理的虚拟现实和增强现实应用特别有益。”
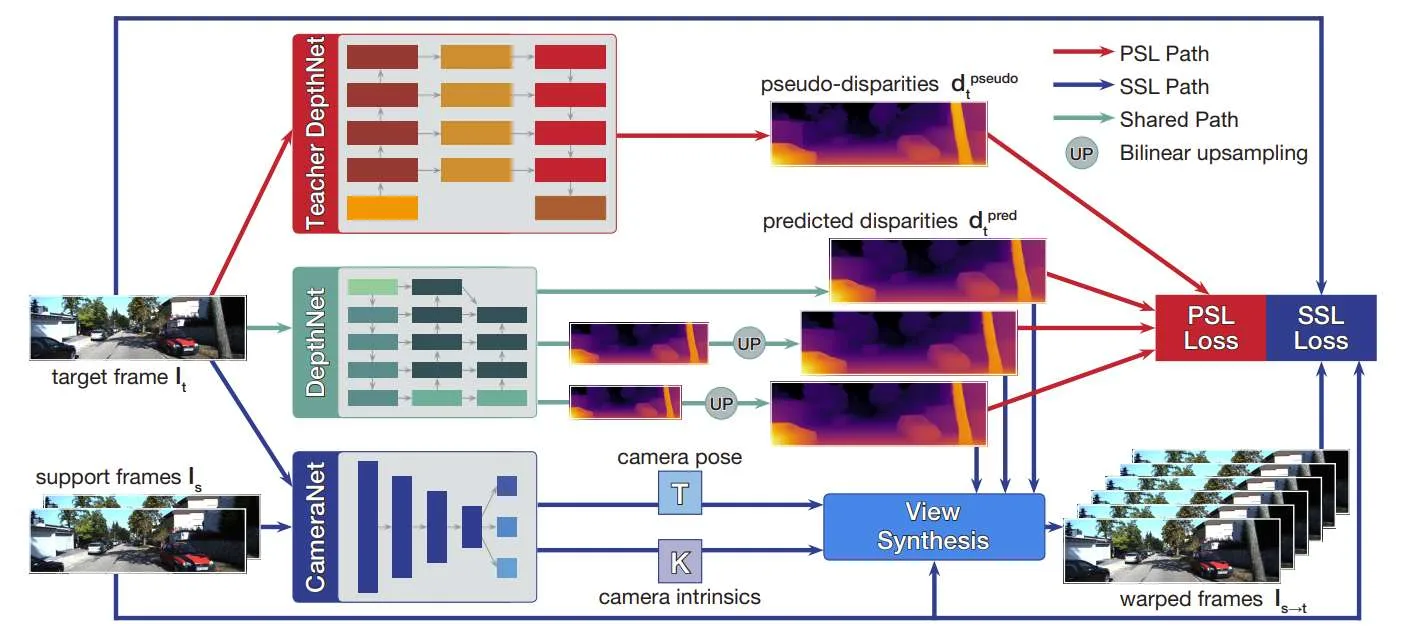
单目深度估计(MDE)是从单个图像输入预测对象相对于camera的距离。低延迟深度估计对于XR应用至关重要,因为它可以确保实时,准确的空间感知以及与虚拟现实和现实世界对象的沉浸式交互,增强用户体验和舒适度。
......(全文 1005 字,剩余 694 字)











