浙江大学+Vivo提出FAGhead从单目视频实现可控Avatar方法

从单目视频中实现完全可控Avatar
(映维网Nweon 2024年12月27日)3D Avatar的高保真重建有着广泛的应用,包括虚拟现实。在一项研究中,浙江大学和vivo团队提出了FAGhead,一种从单目视频中实现完全可控Avatar的方法。
研究人员显式转换传统的三维变形网格(3DMM),并优化了中性3D Gaussians以实现复杂表情的重建。另外,他们采用了一种具有可学习Gaussian点位置的Point-based Learnable Representation Field以提高重建性能。同时,为了有效地管理头像的边缘,引入了alpha渲染来监督每个像素的alpha值。
在开源数据集和捕获数据集的大量实验结果表明,所述方法能够生成高保真的3D Avatar,并且完全控制表情和姿态。
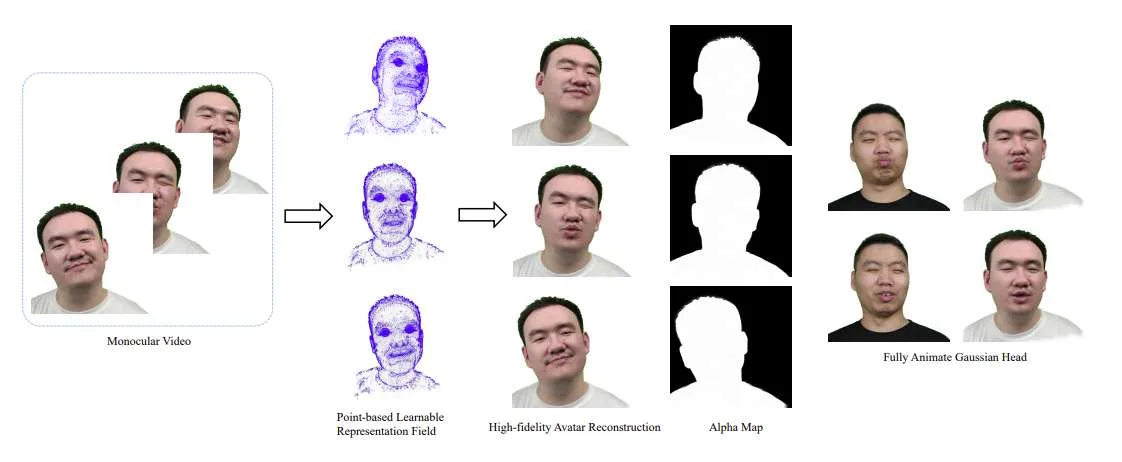
在3D内容创作和虚拟现实技术等一系列应用的推动下,单目视频的3D Avatar重建出现了显著的增长。随着数字人类的发展,对自动合成逼真Avatar的需求越来越大。
以往的研究主要是利用3D变形模型,重点关注形状和表情的变换。但在单视图设置下,所述方法不能满足真实感要求,并且需要精确的几何网格作为先决条件,而这限制了它们的应用。
......(全文 1158 字,剩余 792 字)








