华南理工团队通过网格模型在复杂背景和自遮挡场景下预测生成精确的3D手部网格

在复杂背景和自遮挡场景下生成精确、鲁棒的3D手部网格模型
(映维网Nweon 2024年11月07日)随着虚拟现实和增强现实等技术的快速发展,用户期望与计算机界面的交互更加自然和直观。现有的视觉算法往往难以完成先进的人机交互任务,需要精确可靠的绝对空间预测方法。
在一项研究中,华南理工大学提出一种并行处理根相关网格和根恢复任务的网络模型。所述模型能够从单目RGB图像中恢复camera空间中的3D手部网格。为了促进端到端训练,团队对2D热图使用了一种隐式学习方法,增强了2D线索在不同子任务之间的兼容性。
实验显示,所述方法提高了模型在复杂环境和自遮挡场景下的预测性能。通过对大规模手部数据集FreiHAND的评估,团队证明了所提出模型与最先进的模型相当。
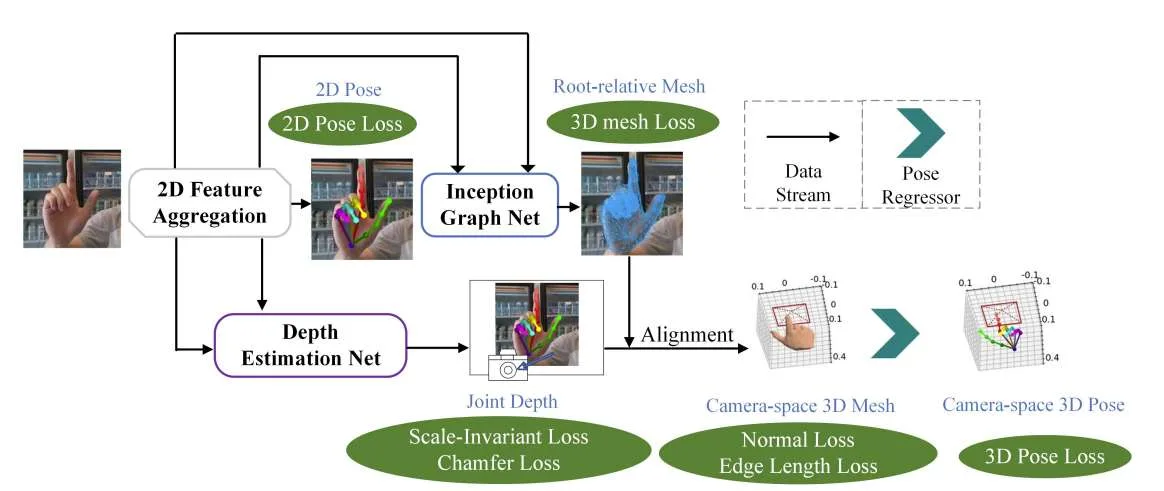
单目3D网格恢复旨在从单幅图像中提取网格顶点的三维位置。精确的3D网格可以增强AR/VR技术的真实性,从而改善沉浸式体验,提高人机交互的交互性水平。
现有的3D手部网格恢复方法大多关注与预定义的根位置(如手腕)相关的坐标,无法准确确定网格的绝对camera空间坐标。这种限制阻碍了它的适用性,使得不适合精确的交互任务,例如远程医疗手术。
......(全文 1605 字,剩余 1175 字)








