中美研究员为AR/VR提出针对NeRF模型的“加速算法”

一种从根本上减少了任何NeRF模型必须执行的工作量,另一种则消除了不规则的DRAM访问
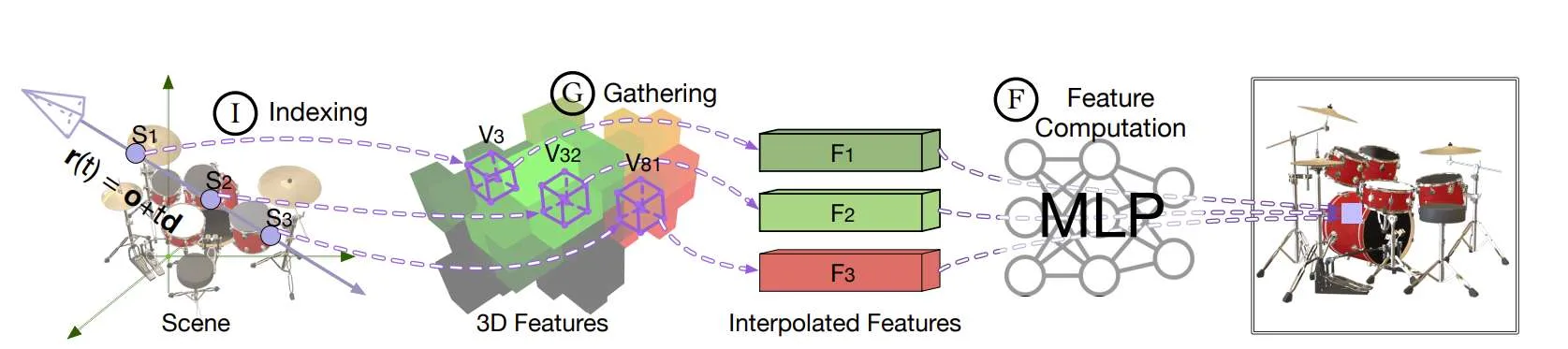
(映维网Nweon 2024年10月28日)神经辐射场NeRF是传统的基物渲染的替代方案。然而,NeRF尚未在虚拟现实和增强现实等资源有限的移动系统中得到应用,这是因为它的速度非常慢。在移动Volta GPU,即便是最先进的NeRF模型通常都只能以0.8 FPS执行。
在一项研究中,上海交大和罗切斯特大学展示了主要的性能瓶颈是算法和架构,并引入CICERO。他们首先介绍了两种算法,一种从根本上减少了任何NeRF模型必须执行的工作量,另一种则消除了不规则的DRAM访问。然后,团队描述了一种消除SRAM组冲突的片上数据布局策略。
CICERO的纯软件实现比移动Volta GPU提供了8.0倍的加速和7.9倍的节能。与专用DNN加速器的基线相比,加速和能量减少分别增加到28.2倍和37.8倍,而所有这一切都只涉及最小的质量损失(峰值信噪比降低小于1.0 dB)。
......(全文 1480 字,剩余 1153 字)








