清华大学提出3D高斯飞溅OccGaussian,可6分钟完成训练,遮挡下产生160FPS高质量人体渲染

将训练和推理速度分别提高了250倍和800倍
(映维网Nweon 2024年10月24日)从单目视频中绘制动态3D人物对于虚拟现实和数字娱乐等各种应用至关重要。大多数方法假设人们处于无遮挡的场景中,而在现实场景中,各种物体可能会导致身体部位遮挡。
以前的方法利用NeRF进行表面渲染来恢复遮挡区域,但这需要一天以上的训练时间和一定的渲染时间,无法满足实时交互应用的要求。
为了解决所述问题,清华大学的一支团队提出了基于3D高斯飞溅的OccGaussian。据介绍,它可以在6分钟内完成训练,并在遮挡输入下产生高达160 FPS的高质量人体渲染。
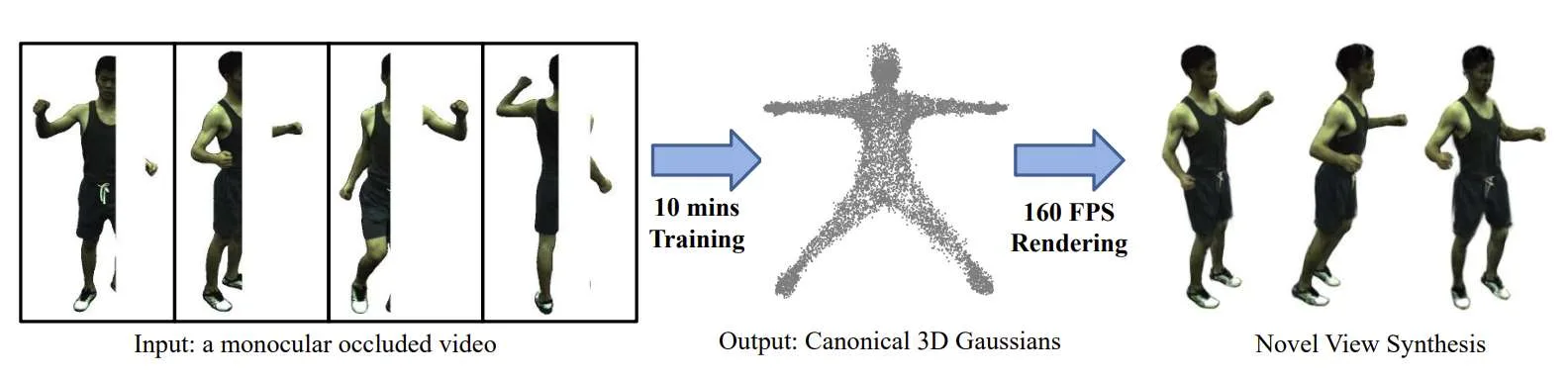
OccGaussian在正则空间中初始化三维高斯分布,在被遮挡区域进行遮挡特征查询,提取聚合的像素对齐特征来补偿缺失的信息。然后,利用高斯特征MLP和遮挡感知损失函数对特征进行进一步处理,以更好地感知遮挡区域。
在模拟和现实世界中进行的大量实验表明,与最先进的方法相比,团队提出的方法实现了相当甚至更好的性能。将训练和推理速度分别提高了250倍和800倍。
......(全文 1426 字,剩余 1051 字)








