日本研究员提出基于事件的三维姿态估计和人体网格恢复方法

仅依赖于事件
(映维网Nweon 2024年10月24日)三维人体捕获是计算机视觉领域的重要课题之一,在虚拟现实等领域有着广泛的应用。然而,传统的帧摄像头受到时间分辨率和动态范围的限制,这在现实世界的应用设置中施加了限制。事件摄像头具有高时间分辨率和高动态范围的优点,但需要发展基于事件的方法来处理具有不同特征的数据。
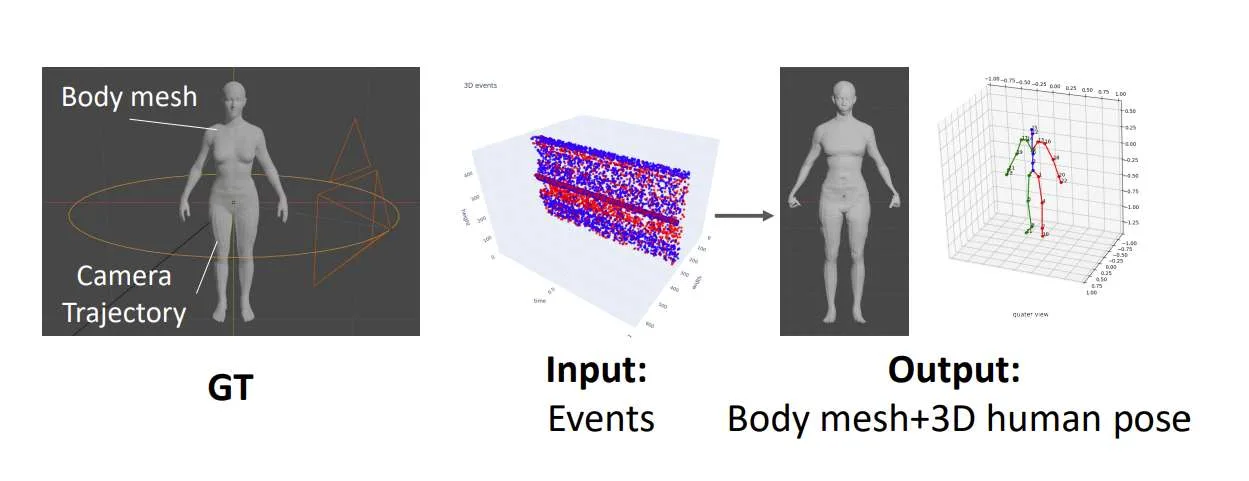
针对这个问题,日本庆应义塾大学提出了一种基于事件的三维姿态估计和人体网格恢复方法。先前基于事件的人体网格恢复研究需要帧(图像)以及事件数据,而团队提出的方法仅依赖于事件。
它通过在静止的身体周围移动事件摄像头来雕刻3D体素,通过衰减光线重建人体姿势和网格,并拟合统计身体模型来保留高频细节。实验结果表明,所述方法在姿态和身体网格的估计精度上都优于传统的基于帧的方法。
......(全文 1260 字,剩余 941 字)








