哈工大引入MSI-NeRF深度学习为鱼眼摄像头合成3D深度信息

哈工大
(映维网Nweon 2024年08月19日)利用鱼眼摄像头进行全景观测在虚拟现实中具有重要意义。然而,传统方法合成的全景图像缺乏深度信息,在VR应用中只能提供三自由度旋转渲染。
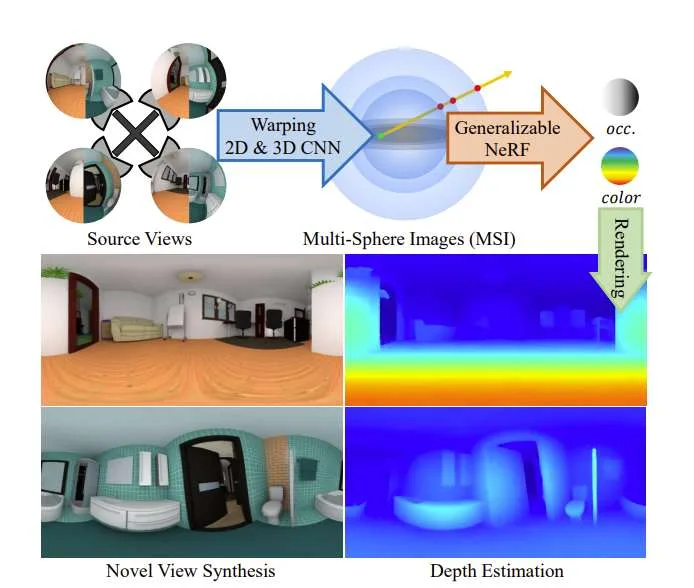
为了充分保留和利用原始鱼眼摄像头中的视差信息,哈尔滨工业大学团队引入了MSI-NeRF,它结合了深度学习全向深度估计和新颖的视图合成。通过对输入图像进行特征提取和变形,他们构建一个多球图像作为代价体。
进一步以空间点和插值后的三维特征向量为输入,构建隐式亮度场,可同时实现全方位深度估计和六自由度视图合成。利用深度估计任务的知识,所述方法仅通过源视图监督来学习场景外观。它不需要新的目标视图,并且可以方便地在现有的全景深度估计数据集上进行训练。网络具有泛化能力,仅使用四张图像就可以有效地重建未知场景。实验结果表明,所述解决方案在深度估计和新视图合成任务方面都优于现有方法。
......(全文 1521 字,剩余 1172 字)