得克萨斯大学为AR/VR提出有效估计和模拟环境声学的新方法ActiveRIR

查看引用/信息源请点击:techxplore
它利用了强化学习,仅依赖于少数声学样本来生成高质量的声学模型
(映维网Nweon 2024年06月03日)一系列的计算工具可以帮助创建VR或AR内容,使得工程师能够生成真实世界环境的逼真模型,包括旨在可靠地表示不同室内环境的物理特性如何转换声音的环境声学模型。
在得克萨斯大学奥斯汀分校,研究人员提出了一种有效估计和模拟环境声学的新方法ActiveRIR。其中,它利用了强化学习,仅依赖于少数声学样本来生成高质量的声学模型。
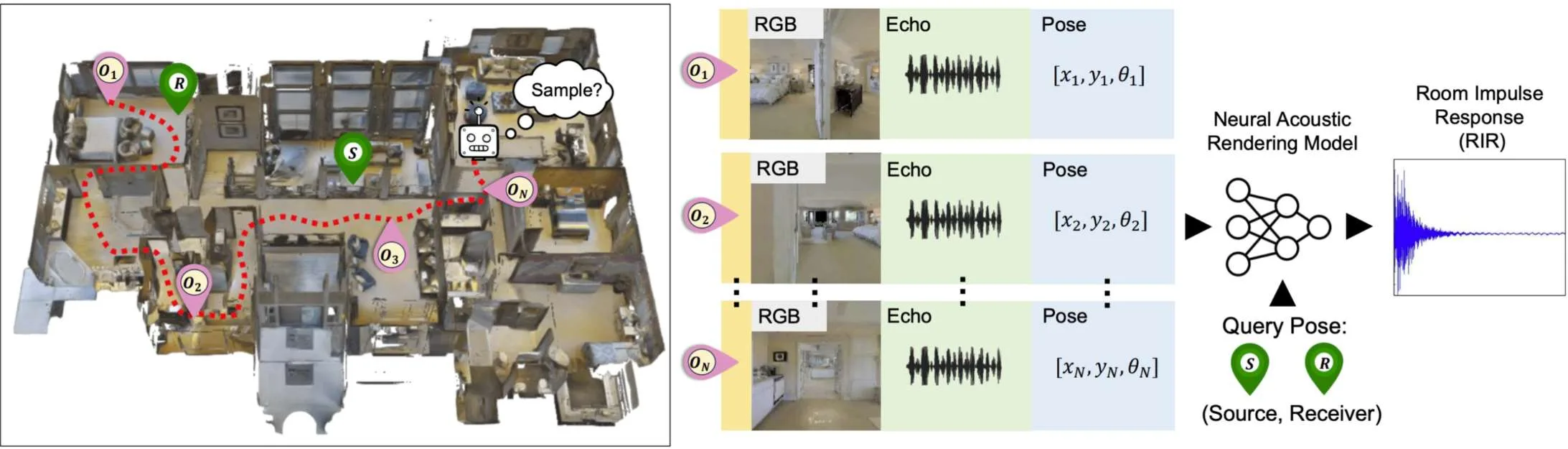
研究人员表示:“‘效率’是指在新的3D环境中使用有限的声学测量集来估计整个场景的声学。估计场景声学可以促进AR/VR应用,因为在AR/VR中,人们希望为3D场景呈现空间合适的声音。”
用于声学建模的传统方法只能在分析从环境中收集的大量音频样本之后进行可靠的估计。这使得它们不切实际,因为它们会耗尽VR/AR设备的电池,并且需要很长时间来进行估计。
团队解释道:“考虑到这一点,我们曾经提出过环境声学的few-shot视听学习,目标是使用其中的极少数视听样本来预测场景声学。然而,这项研究和其他并行研究的局限性在于,它随机选择场景中的几个点来收集样本,这可能是次优的,因为随机选择的点可能不是捕获整个场景声学的最佳样本集。另外,它们假设环境平面图的先验知识,这可能不适用于未曾见的环境,并忽略了物理覆盖所有随机选择的点所需的时间和精力,使其与现实世界的应用程序有点脱节。”
......(全文 1285 字,剩余 763 字)








