苹果专利探索为远程会议中的AR/VR用户交互提供情景上下文说明

提供情景上下文说明
(映维网Nweon 2024年01月03日)对于参与本地会议的远程XR用户,他们可能会看到缺少情景说明的用户表示。例如在本地会议中,本地用户可以伸手抓取一个杯子并喝水,但对于远程XR用户,他们可能只会看到表示本地用户的虚拟角色摆出类似喝水的空举动作,但无法确定这个行为背后的本质意义。
所以在名为“Showing context in a communication session”的专利申请中,苹果介绍了一种在通信会话中提供情景上下文说明的方法。
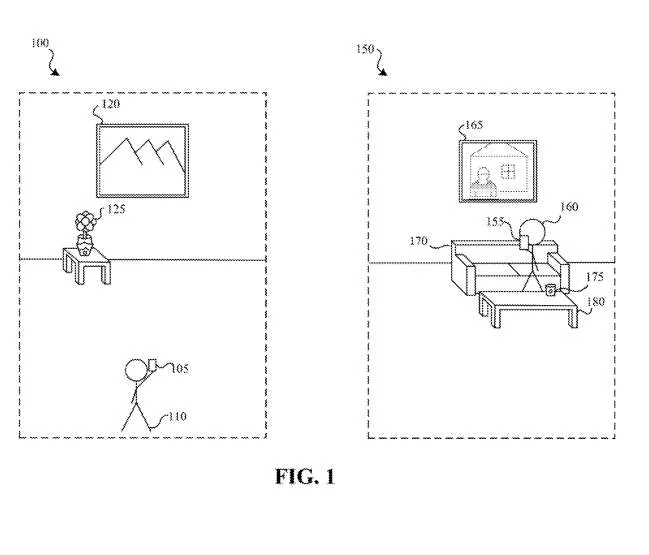
在图1中,物理环境150是一个房间,其中包括壁挂165、沙发170和咖啡桌180上的咖啡杯175。电子设备155包括一个或多个摄像头、麦克风、深度传感器或其他传感器,以捕获关于和评估物理环境150及其中的物体的信息,以及关于电子设备155的用户160的信息。关于物理环境150和/或用户160的信息可用于在通信会话期间提供视觉和音频内容。
......(全文 4138 字,剩余 3831 字)