苹果研究用AI 大模型让移动端CPU、GPU提高数倍至数十倍性能

与CPU和GPU的原始加载方法相比,推理速度分别提高了4-5倍和20-25倍
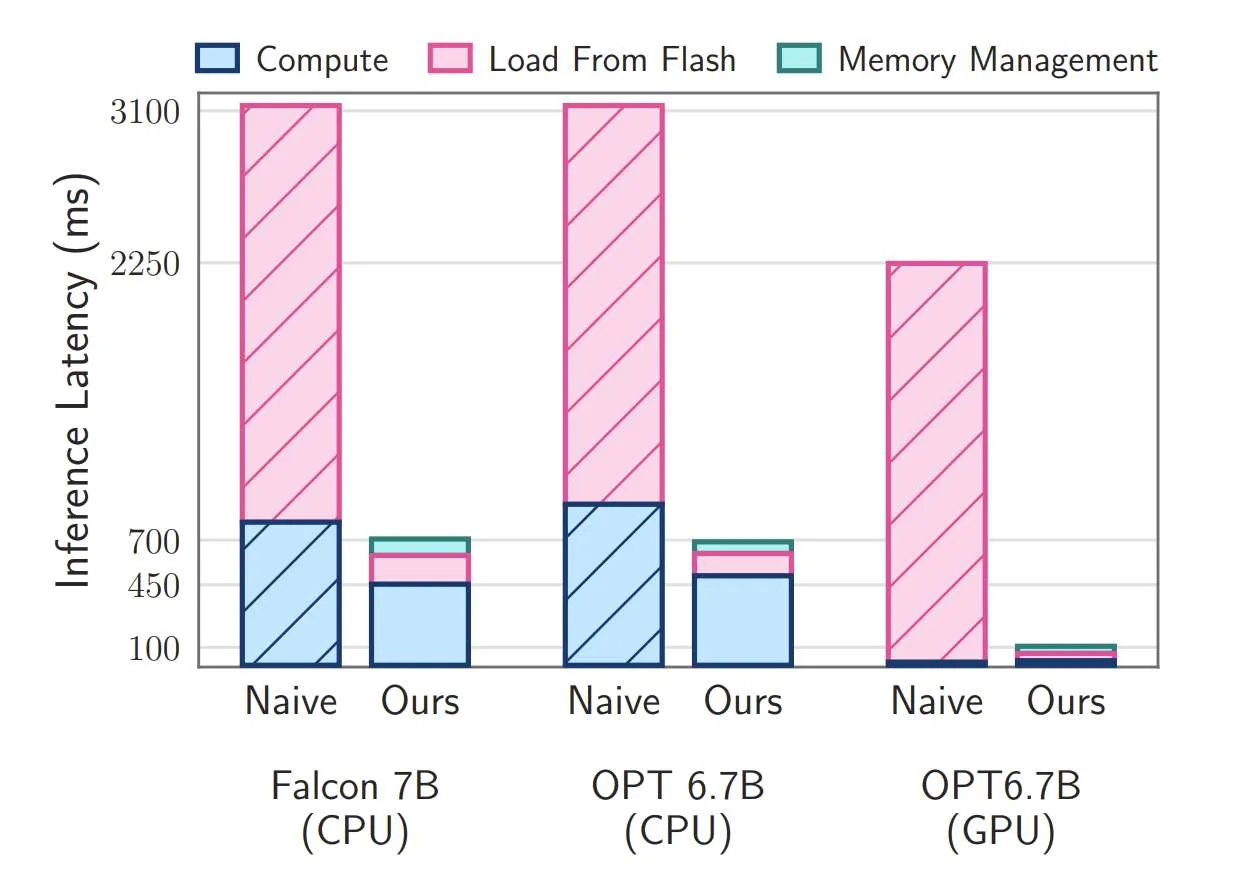
(映维网Nweon 2023年12月25日)苹果日前在一篇论文中介绍了一种可以在超出可用DRAM容量的设备运行大语言模型LLM方法。通过大幅提高内存使用效率,这项新研究将允许资源有限的设备运行2倍于DRAM的LLM。另外与CPU和GPU的原始加载方法相比,推理速度分别提高了4-5倍和20-25倍。
团队的方法包括构建一个与闪存行为相协调的推理成本模型,以在两个关键领域进行优化:减少从闪存传输的数据量和在更大,更连续的数据块中读取数据。在这个闪存信息框架中,苹果主要介绍了两种主要技术。
首先,windowing通过重用先前激活的神经元来策略性地减少数据传输;其次,针对闪存顺序数据访问强度量身定制的“row-column bundling”增加了从闪存读取的数据块的大小。
所述方法使得运行模型的大小达到可用DRAM的两倍。另外与CPU和GPU的原始加载方法相比,推理速度分别提高了4-5倍和20-25倍。同时,研究人员集成了稀疏感知、情景自适应加载和面向硬件的设计,从而为LLM在内存有限设备的有效推理铺平了道路。
相关论文:LLM in a flash: Efficient Large Language Model Inference with Limited Memory
......(全文 476 字,剩余 67 字)











