微软专利介绍控制计算机生成表情的方法,提高Avatar社交性

控制计算机生成表情
(映维网Nweon 2023年12月05日)当前的Avatar存在各种缺点。例如,人们依赖于看到对方的面部表情作为一种交流方式,而大多数Avatar在交谈过程中没有提供用户表情的指示。
在两份同名为“Controlling computer-generated facial expressions”的专利申请中,微软介绍了一种控制计算机生成表情的方法,从而提高Avatar的社交性。
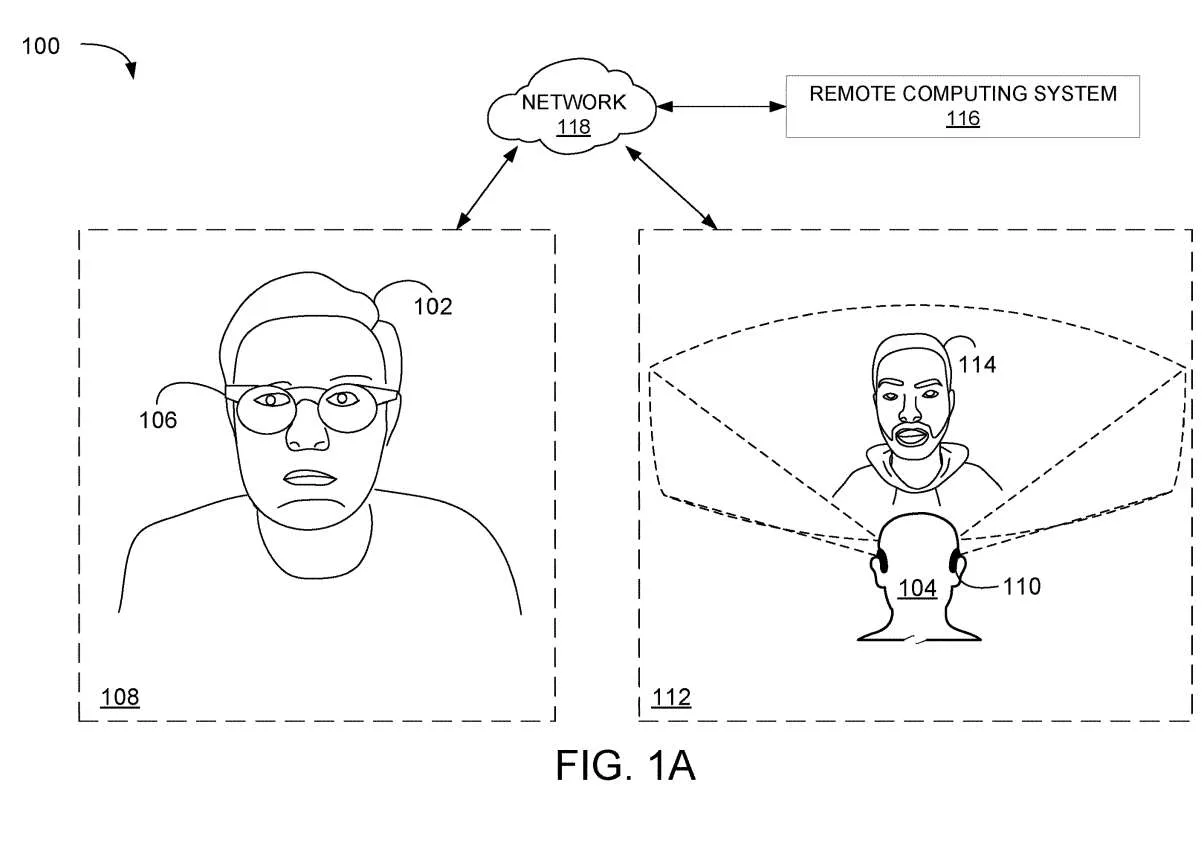
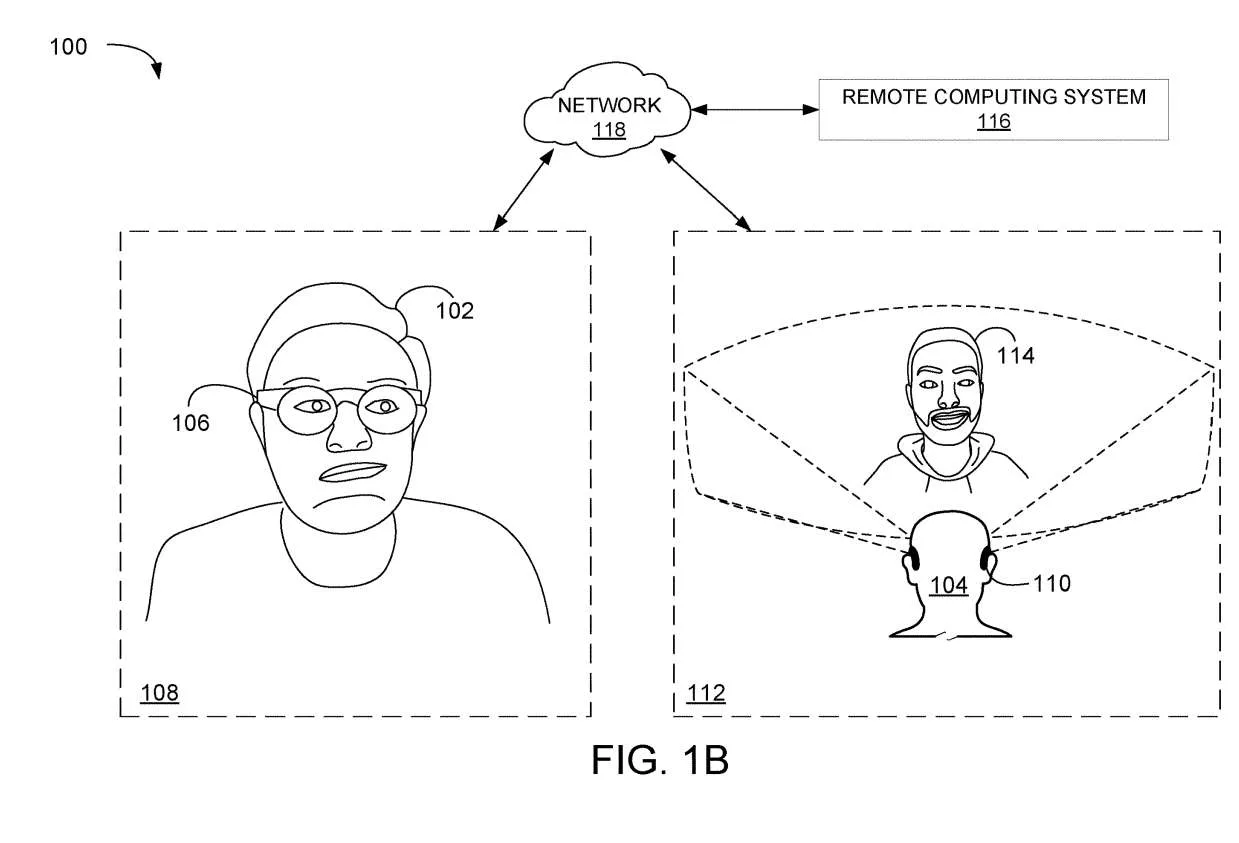
图1A和1B的示例场景使用Avatar来呈现计算机生成面部表情。在AR/VR环境100中,第一用户102和第二用户104正在通信。
在所描述的示例中,第一用户102在第一位置108使用第一头戴式设备106,第二用户104在第二位置112使用第二头戴式设备110。第二头戴式设备110显示代表第一用户102的Avatar114。
......(全文 3400 字,剩余 3168 字)