论文分享:高通如何提升Spaces平台的深度感知和3D重建能力

提升深度感知和3D重建
(映维网Nweon 2023年10月16日)空间网格功能丰富了用户与3D环境交互的方式,并提供了更好的增强现实体验。例如,空间网格允许用户将虚拟棋盘游戏放在桌面之上,以及驱动Avatar在环境中导航。在使用空间网格时,出色用户体验的重要因素之一是准确有效的3D重建。在这篇文章中,高通简要介绍了在提升深度感知和3D重建方面的两份论文贡献。

由深度引导的神经三维场景重建
在没有深度传感器的情况下,现有的体三维神经场景重建方法在将2D特征反投影到3D空间时存在深度模糊问题。在这项论文中,高通建议利用从有效单目深度估计中获得的深度先验来指导特征反投影过程。图1说明了深度引导如何在重建中减少错误特征并改善目标分离。
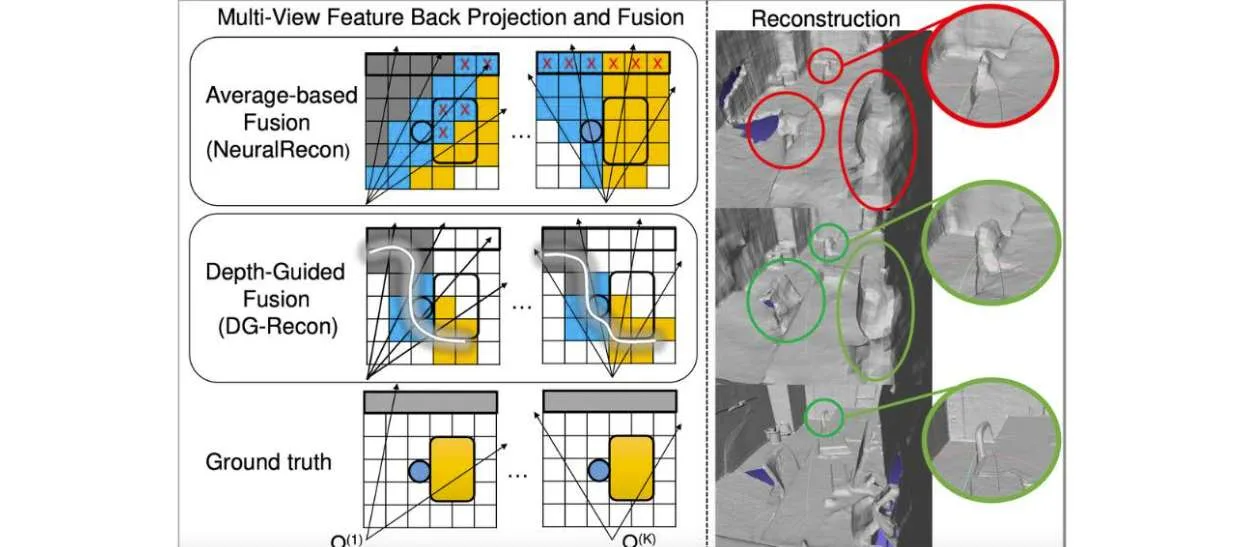
对于基于体三维的场景重建方法,另一个常见缺陷是在多视图特征融合中使用平均值。平均操作丢弃了交叉视图一致性信息,这对于区分表面上和表面上的体素至关重要。高通提出了两种可选择的融合机制:基于方差(var)的融合和基于交叉注意(c-att)的融合。不可学习的方差算子与平均算子一样有效,并且提供了更好的重建。可学习的交叉注意模块进一步改进了重建几何,同时比现有的基于自注意的融合模块效率更高。
......(全文 1330 字,剩余 874 字)