微软专利提出可扩展动态合成声音技术,通过多层优化实现高效HRTF效果

通过多层优化实现高效的HRTF近似
(映维网Nweon 2023年09月27日)头相关传递函数HRTF如何得到适当的实现,诸如HoloLens这样的系统可以产生来自特定位置的逼真虚拟音效。然而,HRTF的计算量十分高昂,所以现有系统会尝试近似HRTF。
不过,尽管现有的系统可以尝试近似HRTF,但微软认为有必要改进声音的合成方式,并降低合成所需的计算水平。这家公司指出,随着越来越多的设备用于合成声音,对如何合成声音的需求会越来越大。但特定设备的计算能力有限,甚至电量有限。
所以在名为“Efficient hrtf approximation via multi-layer optimization”的专利申请中,微软提出了一种可扩展的动态合成声音技术,通过多层优化实现高效的HRTF近似。
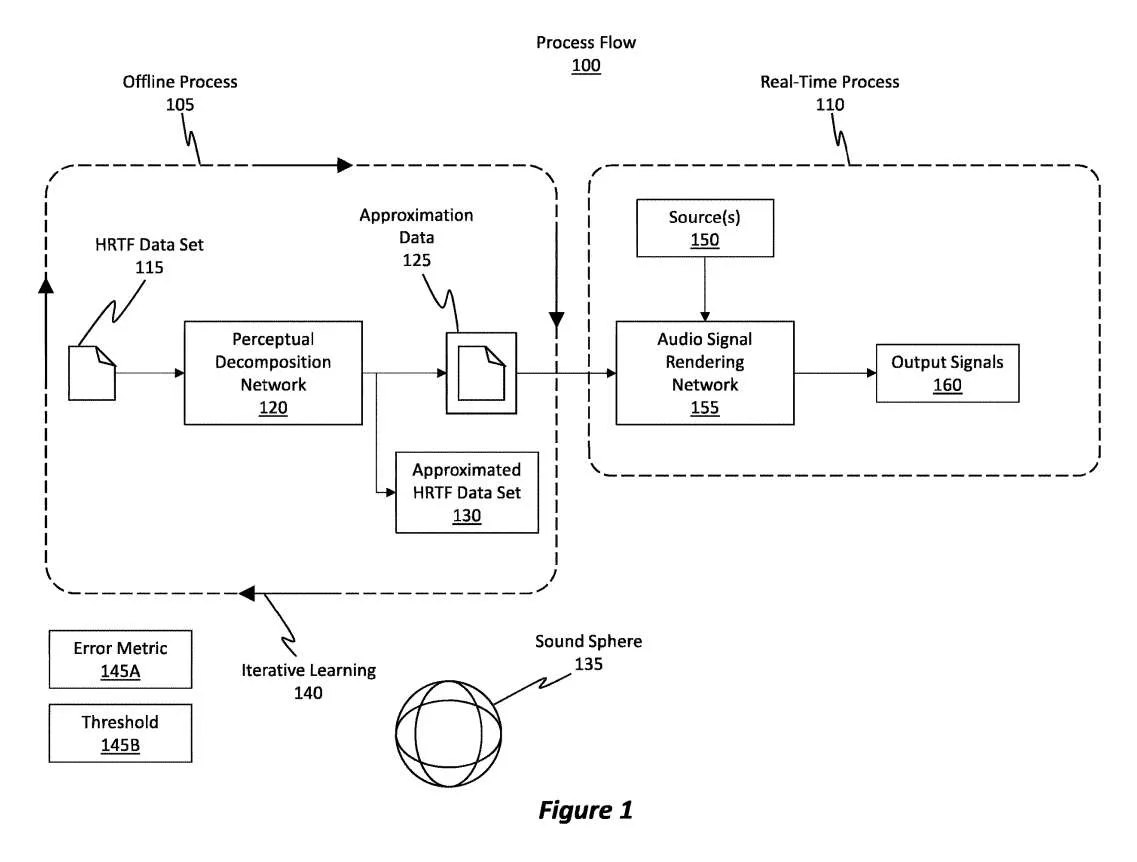
图1说明了相关的流程100。所述进程100一般包括两个进程,如离线进程105和实时进程110。
离线过程105是指感知分解过程,其中网络使用HRTF数据集来导出近似数据。通过离线方式,意味着可以在呈现音频信号之前的任何时间执行离线进程。
......(全文 6425 字,剩余 6084 字)