Meta开源生成式AI 音频工具AudioCraft

从基于文本的用户输入生成高质量,逼真的音频和音乐
(映维网Nweon 2023年08月04日)想象一下,一个专业的音乐家不必在乐器弹奏一个音符就能探索新作品;独立游戏开发者在预算有限的情况下通过逼真的音效和环境声来填充虚拟世界;一个小企业主可以轻松地为最新的Instagram贴文添加配乐。
这就是Meta AudioCraft的承诺,而团队已经将其开源。这个简单框架在对原始音频信号进行训练后,可以从基于文本的用户输入生成高质量,逼真的音频和音乐。

AudioCraft包括三个模型:MusicGen、AudioGen和EnCodec。MusicGen接受了Meta所有和特别授权的音乐的训练,可从基于文本的用户输入中生成音乐;而AudioGen则接受了公共声音效果的训练,可从基于文本的用户输入中生成音频。
现在,团队正在为社区带来EnCodec解码器的改进版本;可以产生环境声音和音效的预训练AudioGen模型;以及所有AudioCraft模型代码。
团队指出:“我们非常高兴能够为研究人员和从业者提供访问权限,这样他们就可以第一次用自己的数据集训练自己的模型,并帮助推进最先进的技术。”
轻松地从文本到音频
近年来,包括语言模型在内的生成式人工智能模型已经取得了巨大的进步,并显示出了非凡的能力。然而,这主要集中在图像、视频和文本的生成式人工智能方面,音频似乎总是有点落后。尽管相关领域已经存在一定的研究,但它们非常复杂,而且不是十分开放。
生成任何类型的高保真音频都需要以不同的尺度对复杂的信号和模式进行建模,而音乐则可以说是最具挑战性的音频类型。用人工智能生成连贯的音乐通常是通过使用MIDI等方式来解决。然而,所述方法并不能完全把握音乐中表现的细微差别和风格元素。
AudioCraft系列模型能够产生具有长期一致性的高质量音频,并且可以通过自然界面轻松交互。与之前在同一领域的研究相比,AudioCraft简化了音频生成模型的整体设计,允许人们可以完整地使用Meta在过去几年里开发的现有模型,同时能够突破极限,开发自己的模型。
AudioCraft适用于音乐和声音生成和压缩,一切都在同一个地方发生。因为它十分容易构建和重用,所以想要构建更好的声音生成器、压缩算法或音乐生成器的人员可以在相同的代码库中完成所有工作,并在其他人的基础上进行拓展。
一个简单的音频生成方法
从原始音频信号生成音频十分具有挑战性,因为它需要建模非常长的序列。以44.1 kHz(音乐录音的标准质量)采样的数分钟典型音轨是由数百万个时间步组成。相比之下,基于文本的生成模型使用作为子词处理的文本,每个样本只代表几千个时间步。
为了解决这个问题,团队使用EnCodec神经音频编解码器从原始信号中学习离散音频token,这为音乐样本提供了一个新的固定“词汇表”。然后,在离散的音频token训练自回归语言模型,以在使用EnCodec的解码器将token转换回音频空间时生成新的token和新的声音和音乐。
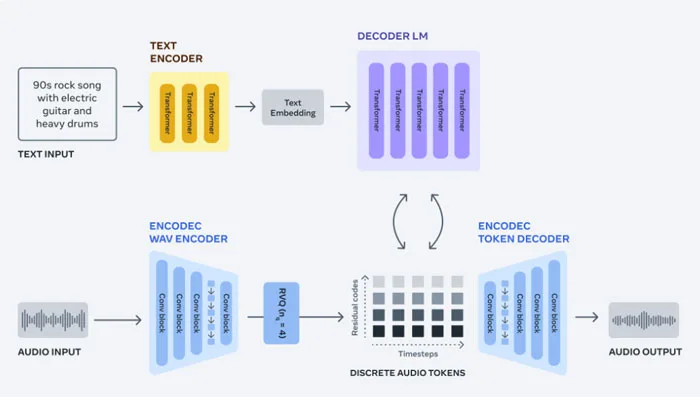
EnCodec是一种有损神经编解码器,专门用于压缩任何类型的音频并以高保真度重建原始信号。它由一个带有残余矢量量化瓶颈的自编码器组成,可产生具有固定词汇表的多个并行音频token流。不同的流捕获不同级别的音频波形信息,从而允许你从所有流中重建高保真度的音频。
训练音频语言模型
然后,研究人员使用单个自回归语言模型对来自EnCodec的音频token进行递归建模,并介绍了一种简单的方法来利用并行token流的内部结构,从而生成高质量的声音。
通过AudioGen,它们证明可以训练人工智能模型来执行文本到音频生成的任务。给定声音场景的文本描述,模型可以生成具有真实记录条件和复杂场景情景描述所对应的环境声音。
另外,MusicGen是专门为音乐生成量身定制的音频生成模型。音轨比环境声音更复杂,在创作新音乐作品时,产生连贯的样本尤为重要。MusicGen已经接受了大约40万份录音以及文本描述和元数据的训练,总计为Meta拥有或专门为此目的授权的2万小时音乐。
在这项研究的基础上
Meta将继续致力于高级生成AI音频模型背后的研究。作为AudioCraft的一部分,团队进一步提供了新的方法,通过基于扩散的离散表示解码方法来提高合成音频的质量。研究人员计划继续研究音频生成模型的更好可控性,探索额外的调节方法,并推动模型捕获依赖关系的能力。最后,他们将继续研究在音频上训练的这种模型的局限性和偏差。
团队正在努力改进当前的模型,从建模的角度提高它们的速度和效率,并改进控制模型的方式,从而开辟新的用例和可能性。
当然,Meta认识到用于训练模型的数据集缺乏多样性。特别是,所使用的音乐数据集包含更大比例的西式音乐,并且仅包含以英语编写的文本和元数据的音频-文本对。通过分享AudioCraft的代码,团队希望其他研究人员可以更容易地测试新方法,以限制或消除对生成模型的潜在偏见和滥用。
开源的重要性
Meta指出,负责任的创新不可能孤立地发生。开源研究和结果模型有助于确保每个人都有平等的机会。团队正在向研究界提供不同大小的模型,并详细说明相关的人工智能实践方法构建模型。
这家公司总结道:“AudioCraft是生成式人工智能研究的重要一步。我们相信,我们开发的简单方法可以成功地生成鲁棒、连贯和高质量的音频样本,这将对考虑听觉和多模态接口的先进人机交互模型的发展产生有意义的影响。我们非常期待大家会用它来创造什么。”







