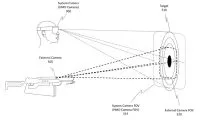
微软为AR/VR空间音频提出了一种声音参数化建模

声音的参数化建模
(映维网Nweon 2023年07月17日)实时声学效果的建模和渲染是非常密集的计算。如果没有复杂和昂贵的硬件,就很难呈现出真实的声学效果。对真实或虚拟场景的声学特性进行建模,同时允许声源和听者的移动,这是一个困难的问题,特别是对于复杂的场景。
在名为“Parameterized modeling of coherent and incoherent sound”的专利申请中,微软就介绍了一种声音的参数化建模。
在对场景的声学效果进行建模时,需要考虑的一个重要因素是声音到达听者处的延迟。一般来说,听者收到声波的时间会向听者传达重要的信息。
例如,对于一个由声源引入场景的给定的波脉冲,压力响应到达听者的时候是一系列的峰值,每个峰值都代表了声音从声源到听者的不同路径。每个峰值的时间、到达方向和声能都取决于各种因素,如声源的位置、听者的位置、场景中结构的几何形状以及结构的组成材料。
......(全文 4074 字,剩余 3749 字)