Meta研究员:3D手部姿态质量显著影响动作识别性能

自中心手部姿态数据集
(映维网Nweon 2023年06月20日)识别人类活动是计算机视觉领域的一个重要课题。随着增强现实和虚拟现实系统的进步,从自中心(第一人称)角度识别动作的需求越来越大。诸如微软HoloLens、Magic Leap和Meta Quest等设备通常配备了自中心摄像头,以捕获用户与真实世界或虚拟世界的交互。
在这种场景中,用户通过双手操纵对象是一种非常重要的交互方式。特别是,手的姿态在理解和实现手-物交互、基于姿态的动作识别和交互界面中起着核心作用。社区已经提出了数个用于理解自中心活动的大规模数据集,如EPICKITCHENS、Ego4D和Assembly101。特别是,Assembly101强调了3D手在识别程序性活动的重要性,例如组装玩具。
值得注意的是,Assembly101的作者发现,对于组装动作的分类,从3D手部姿态中学习比仅仅使用视频特征更有效。然而,所述研究的一个缺点是,Assembly101中的3D手部姿态注释并不总是准确,因为它们是从现成的自中心手部追踪器计算出来的。如图1可以观察到,提供的姿态往往是不准确,特别是当手被物体遮挡时。
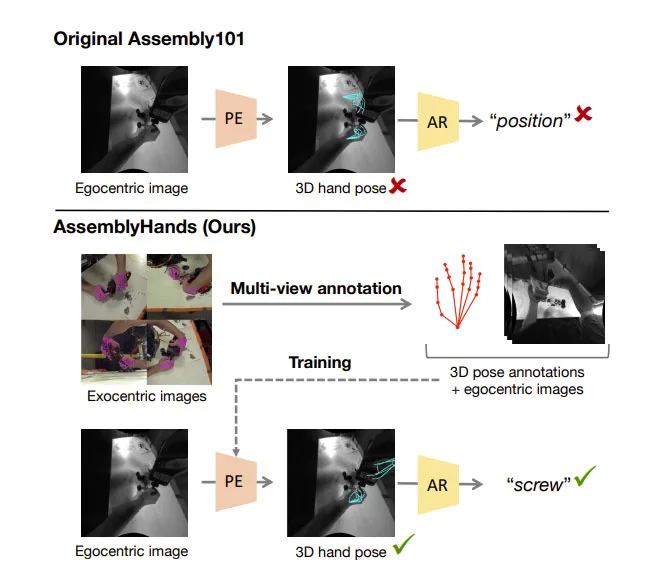
因此,之前的研究给社区留下了一个未解决的问题:3D手部姿态的质量如何影响动作识别性能?
为了系统地回答这个问题,由Meta和东京大学的研究人员提出了一个名为AssemblyHands的新基准数据集。它包括从Assembly101采样的总共3.0M图像,并使用高质量的3D手部姿态注释。他们不仅获得了手动标注,而且利用它们来训练精确的自动标注模型,通过第三人称图像的多视图特征融合。
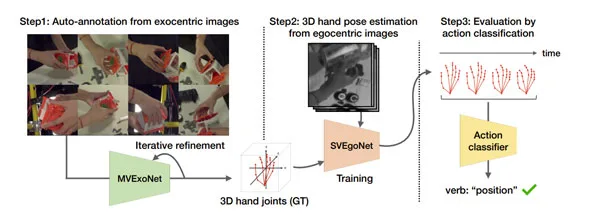
如图2所示。模型实现了4.20 mm的平均关键点误差,比Assembly101中提供的原始注释低85%。这种自动管道使得能够有效地将注释扩展到来自34个主题的490K以自中心图像,令AssemblyHands成为迄今为止最大的自中心手部姿态数据集,包括规模和主题多样性方面。
......(全文 4670 字,剩余 4066 字)











