研究员提出视觉位置识别VPR地图致密化新方法

查看引用/信息源请点击:techxplore
提高相关深度学习算法的性能
(映维网Nweon 2023年05月30日)视觉位置识别VPR是识别特定图像拍摄位置的任务。计算机科学家已经开发了各种深度学习算法来有效地解决这一任务,帮助用户确定在已知环境中捕获图像的位置。
日前,荷兰代尔夫特理工大学介绍了一种新的方法来提高相关深度学习算法的性能。其中,他们提出的方法是基于一种称为连续位置描述符回归CoPR的新模型。团队表示:“我们的研究源于对VPR性能基本瓶颈的反思,以及相关的视觉定位方法。”
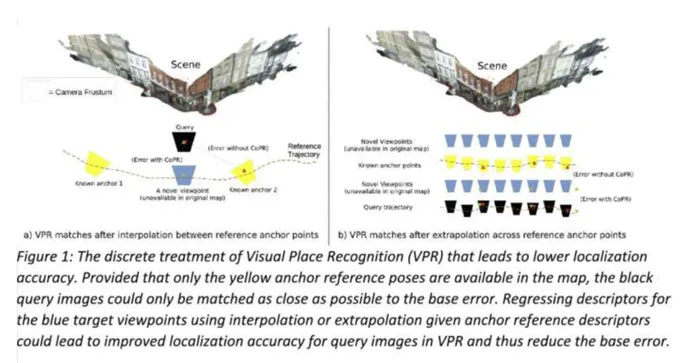
首先,研究人员讨论了“感知混叠”的问题,即具有相似视觉外观的不同区域。举个简单的例子,假设正在收集高速公路最右侧车道的行驶车辆的参考图像。如果稍后针对同一条高速公路的最左侧车道,最准确的VPR估计将是匹配附近的参考图像。然而,视觉内容可能无法正确匹配不同的高速公路路段,因为系统同时会收集在最左侧车道的参考图像。
......(全文 2459 字,剩余 2119 字)








