Meta研究:用于实时XR工作负载的多模型ML基准测试

实时多模型ML基准测试
(映维网Nweon 2023年05月29日)基于机器学习的应用程序正变得越来越普遍。机器学习在视觉和语音识别任务中的成功推动了越来越复杂用例的发展。例如,元宇宙结合了多个单元用例(例如图像分类和语音识别)来创建更复杂的用例。
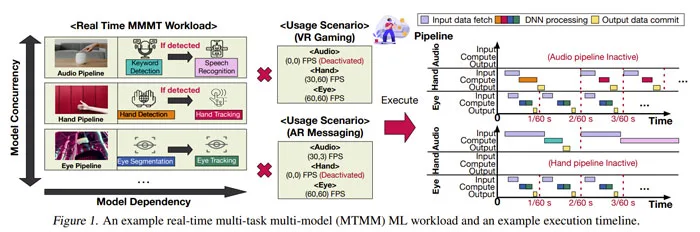
应用程序工程师越来越依赖于可组合性。他们不是为用例开发不同的大型模型,而是将多个较小而专的ML模型组合在一起来组成任务功能。在名为《XRBench: An Extended Reality Machine Learning Benchmark Suite for the Metaverse》的论文中,加州大学、Meta、乔治亚理工学院和哈佛大学的研究人员重点关注了这类机器学习的工作负载,即多任务多模型MTMM,特别是在元宇宙情景中。
团队开发了一个用于实时XR工作负载的多模型ML基准测试,并为每个模型提供了开源参考实现,从而支持广泛的采用和使用。另外,他们为XRBENCH建立了新的评分指标,从而捕获实时MTMM应用程序的关键需求并进行定量评估。XRBENCH目前已经作为一个开源项目托管至GitHub。
......(全文 5914 字,剩余 5560 字)











