Meta研究优化AR/VR环境的物品对象视觉可视化查找

例如通过指向真实世界定位的3D箭头来找到他们的物品
(映维网Nweon 2023年05月15日)可视化查询本地化的任务可以描述为“我最后一次看到X是什么时候”的问题,其中X是由visual crop表示的对象查询。在Ego4D设置中,这个任务旨在从“情景记忆”中检索对象,并由VR头显或AR眼镜等设备支持。
这种功能的实际应用是通过预先注册的对象中心图像来定位用户的项目。一个功能强大的视觉查询定位系统将允许用户通过短暂的回放或通过指向真实世界定位的3D箭头来找到他们的物品。
问题的当前解决方案依赖于所谓的Siam-detector。Siam-detector模型设计允许通过独立地将查询与所有对象建议进行比较来合并查询示例。在对给定视频进行推理期间,视觉查询是固定的,检测器在自中心视频记录中的所有帧运行。
尽管现有的方法在查询对象检测性能方面提供了富有希望的结果,但它依然存在domain和task bias,尤其是当查询对象不在视线范围内时。当前模型对每个对象proposal的独立评分加剧了所述问题,因为基线模型学会对表面相似的对象给予高分,而忽略其他proposal来重新评估分数。
在名为《Where is my Wallet? Modeling Object Proposal Sets for Egocentric Visual Query Localization》的研究论文中,Meta和沙特阿卜杜拉国王科技大学的研究人员指出,通过使用增强对象建议集训练条件情景检测器,可以在很大程度上解决bias。
他们提出的检测器基于超网络架构,允许结合开放世界的视觉查询,以及基于trasnformer的设计,从而根据来自其他proposal的情景参与检测推理。他们将这个模型称为CocoFormer。
CocoFormer有一个条件投影层,它从查询中生成一个转换矩阵,然后将转换应用于proposal特征,以创建以query-conditioned proposalembeddings。接下来,query-aware proposal embeddings馈送到set-transformer,这有效地允许模型利用相应帧的全局情景。
在实验中,CocoFormer超越了Siam RCNN,并且在作为超网络的不同应用中更灵活,例如多模式查询对象检测和FSD。另外,CocoFormer增加了为视觉查询定位建模对象的能力,因为它通过合并条件情景来解决domain bias。但是,它依然受到当前训练策略引起的task bias的影响。
为了缓解这种情况,团队从标记和未标记的视频帧中对proposal set进行采样,这样可以收集更接近真实分布的数据。具体地说,通过视图中同一对象的自然视点变化来扩大正查询帧训练对,同时创建包含背景帧中对象的负查询帧训练配对。
从本质上讲,研究人员以平衡的方式从框架中对proposal集进行采样。他们将一个框架中的所有对象收集为一个set,并通过两个set-level问题将任务解耦:(1)查询对象存在吗?(2) 与查询最相似的对象是什么?
由于训练bias问题只存在于第一个问题中,团队对正/负proposal set进行采样以减少它。请注意,这是一个独立的帧采样过程,因为domain bias会削弱对自中心视图中对象的理解,而task bias会隐式阻碍视觉查询检测的准确性。
总体而言,实验表明,使对象查询和proposal set多样化,并利用全局场景信息可以明显提高查询对象检测。例如,使用未标记帧进行训练可以将检测AP从27.55%提高到28.74%,而优化条件检测器的架构可以将AP进一步提高到30.25%。另外,视觉查询系统可以在2D和3D配置中进行评估。在VQ2D中,可以观察到从基线0.13到0.18的显著改善。VQ3D则展示了所有指标的一致改进。
方法
视觉查询(VQ)任务将查询对象的静态图像以及以自中心视频记录作为输入。预期输出是对象最后一次出现在视频中时的定位。具体地,视觉查询2D定位任务(VQ2D)要求输出响应是目标对象最后出现的时间段的每个帧的2D bounding box。
另外,视觉查询3D定位任务(VQ3D)同时需要从当前camera位置指向目标对象的3D bounding box的3D位移向量。当用户通过显示一个图像示例来询问对象的位置时,VQ适用,例如,“这(钱包的照片)在哪里?”。
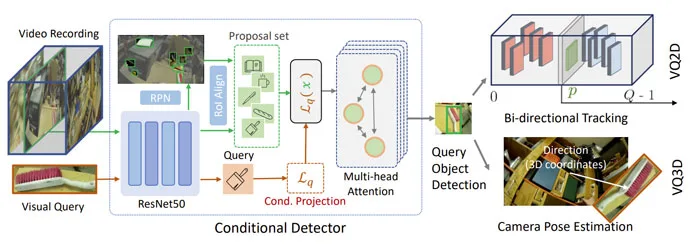
团队开发了一个检测+定位管道来解决VQ任务,过程如图2所示。给定查询对象o的visual cropv,通过条件检测器在视频记录的所有帧(表示为f)中基于v来检测o。因此,检测器的输入是视觉查询裁剪v和视频帧f,并且输出是在帧中具有置信度得分(x,y,w,h,c)的bounding box。
更具体地说,他们提出的检测器使用具有ResNet-50视觉主干的RPN从输入帧生成bounding box建议{b1,···,bn},然后进行RoI-Align操作以提取bounding box特征{F(b1),··,F(bn)}。
另一方面,visual crop通过相同的主干,并从条件投影层生成唯一的变换。将转换应用于proposal特征,为multi-head attention layer生成query-aware proposal embeddings,multi-head attention layer从proposal set中预测目标对象。团队通过Ego4D中定义的VQ任务来验证我们的查询对象检测结果,并严格遵循这两项任务的episodic memory基线,以在视频和真实世界坐标中定位查询对象。
对于VQ2D,从最近的检测峰值运行双向跟踪器,并预测时空bounding box轨迹。对于VQ3D,将camera姿态估计应用于视频帧,并输出从camera位置到预测对象的位移矢量。
VQ2D的现有方法遵循简单的对象查询成对比较策略。这种公式的一个缺点是,与查询的独立比较限制了模型的理解,因为它只基于个体相似性来强制决策,而忽略了整个proposal set。研究人员以自适应的set-transformer架构的形式结合全局set-level情景,从而直接解决这种模型bias。他们基于transformer的模型将top proposal的查询proposal特征对作为一个set,并使用self attention来学习查询与所有选定proposal之间的交互。
团队将模型命名为Conditional Contextual Transformer或CocoFormer,因为它提供了set-level的情景,并且以提供的查询为条件。具体来说,CocoFormer包含一个条件投影层,并用于为每个候选proposal生成与查询相关的embeddings,以及一个self attetion块,用于利用camera视图中可用proposal set的全局情景。
条件投影层Lq(x)基于给定条件(查询)q生成变换(例如Lq),然后将条件相关变换并行应用于输入x。变换生成器实现为具有大小(Cout,Cin,Ccond)的3D张量,其分别是输出、输入和条件的维度。
所述张量首先对最后一个维度上的查询q进行运算,产生Cout×Cin线性变换。然后,将变换应用于输入x以获得新的embeddings。在实践中,将visual crop的特征作为条件,q=F(v),并将proposal set作为输入x={Fb1,··,Fbn}。
因此,该层的输出是查询bias proposal embeddings,即{LF(v)(F(b1)),···,LF(v)F(bn)}。与FSD类似,只有变换生成过程在训练中得到优化。
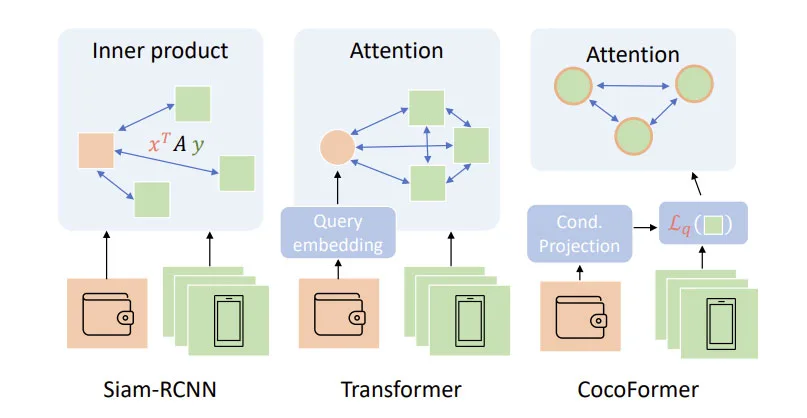
图3将CocoFormer与基线和transformer变体进行了比较。Baseline Siam RCNN有一个成对的交互生成来决定每个propoal是否是目标对象。所有对的独立比较导致对全局情景建模的能力有限。或者,直接应用cross-attention或self-attention可以丰富情景感知,但模型很难学会将每个proposal与视觉查询进行比较。
CocoFormer将自self attetion应用于每个候选proposal的查询条件embeddings,因此它有更好的能力基于查询选择元素并利用全局情景。
结果
CocoFormer是一个查询条件情景transformer,它包含一个条件投影层,用于基于查询对象转换候选proposal,并包含multi-head attention来操作转换。团队通过应用完全相同的训练/验证协议比较了表4中几种可能的查询检测模块。
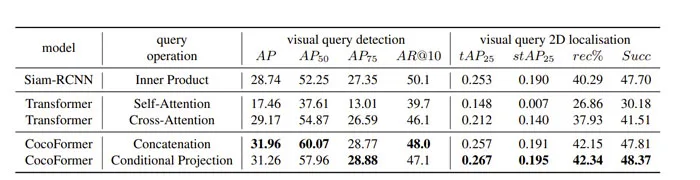
基线模型SiamRCNN如表4的第一行所示。与表1中报告的查询检测结果相比,Siam RCNN从改进的训练策略中受益匪浅。
在表4的第二部分中,团队同时比较了基于普通transformer的架构。Self-Att意味着将具有可学习embeddings的视觉查询作为self attetion layer中的额外标记,而Cross-Att意味着将每个候选proposal作为查询,并将视觉查询作multi-head attention中的关键字和值。具有cross attetion的transformer在检测AP和AP50方面的工作略好于基线,但由于在严格设置(例如AP75)中定位不准确,它在完整的VQ2D中表现不佳。
CocoFormer的整体性能优于其他设计。表4中一个有趣的观察结果是,与其他检测指标相比,查询检测中的AP75与VQ2D分数的相关性更好。完整CocoFormer在严格的图像级查询检测设置和VQ2D中提供了明显的优势。
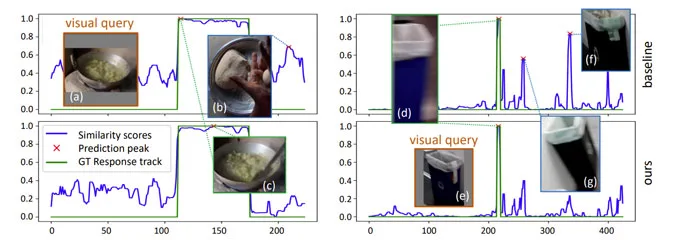
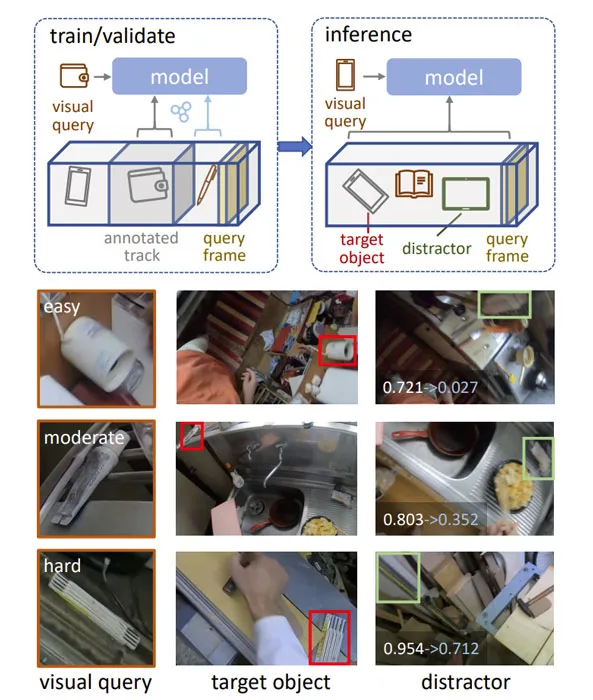
图5可视化了两个示例视频的预测。在煎锅视频中,两种方法都在不同的视图中找到查询对象,但基线模型报告了干扰物的高相似性分数,因为干扰物是一个装有食物的金属容器。
蓝色垃圾桶视频更具挑战性,因为查询图像裁剪是在低光照条件下拍摄的。因此,基线检测到的黑色垃圾桶比ground truth具有更相似的视觉外观。团队的方法能够对全局情景进行建模,并将黑色莱吉童报告为负值。
延伸阅读:Where is my Wallet? Modeling Object Proposal Sets for Egocentric Visual Query Localization
总的来说,团队研究了自中心视觉查询定位这一具有挑战性的问题。他们从解决数据集和task bias开始,并建议在训练期间扩展有限的注释和动态丢弃对象建议。另外,他们提出了CocoFormer,这是一个新的基于transformer的模块,允许在合并查询信息时考虑对象proposal set情景。实验表明,所提出的自适应改进了自中心查询检测,从而在2D和3D配置中实现了更好的视觉查询定位系统。CocoFormerranked在第二次Ego4D挑战中的VQ2D和VQ3D任务中分别获得第一和第二名,并在FSD检测任务中获得SOTA性能。
......(全文 2848 字,剩余 0 字)








