Meta研究提出3D可变形、可重照明的虚拟环境眼镜佩戴效果模型MEGANE

以数据驱动的方式对眼镜架和人脸之间的几何和光度相互作用进行建模
(映维网Nweon 2023年05月04日)人类是群居动物,而我们的着装和配饰是在日常生活中自我表达和沟通的关键要素。随着社交逐渐扩展到网络世界,随之而来的是对服装和配饰数字化的需求。
在名为《MEGANE: Morphable Eyeglass and Avatar Network》的研究论文中,澳大利亚国立大学和Meta的研究人员专注于眼镜的建模,因为眼镜是全球数十亿人的日常配件。特别是,他们认为,要实现真实感,仅仅对眼镜进行单独建模并不足够,同时必须考虑眼镜与面部的相互作用。
从几何角度来看,眼镜和人脸不是刚性,它们在接触点相互变形。所以,眼镜和面部的形状不能独立地确定。类似地,它们的外观是通过全局光传输耦合,阴影和相互反射可能会出现并影响辐射。因此,对所述相互作用进行建模的计算方法对于实现真实感十分有必要。
原来的方法并不能忠实地重建现实世界中存在的所有几何和光度相互作用,或者动画结果通常会出现视图和时间不一致的问题。尽管新兴起的神经渲染方法以3D一致的方式实现了人头和一般物体的真实感渲染,但相关方法没有考虑对象之间的相互作用,并导致不可信的对象组合。
与现有方法相比,团队的目标是根据图像观测,以数据驱动的方式对眼镜架和人脸之间的几何和光度相互作用进行建模。为此,他们推出了MEGANE。
这一种可变形和可重照明的眼镜模型代表了镜框的形状和外观及其与人脸的相互作用。为了支持拓扑和渲染效率的变化,研究人员使用了一种将表面几何和体三维表示相结合的混合表示。
由于混合表示在眼镜之间提供了明确的对应关系,可以根据头部形状对其结构进行细微的变形。最重要的是,模型受到高保真度生成人头模型的制约,使其能够专门针对佩戴者的变形和外观变化。

类似地,团队为可变形人脸模型提出了眼镜条件下的变形和外观网络,以纳入戴眼镜引起的交互效应。他们同时提出了一种可以为任何镜片产生逼真反射和折射,并简化捕获任务的分析透镜模型,从而能够以事后方式插入镜片。
为了在新的照明中联合渲染眼镜和人脸,他们将物理启发的神经重照明纳入所提出的生成式建模中。所述方法在给定视图、点光源位置、可见性和具有多个波瓣大小的镜面反射的情况下推断输出辐射。
实验显示,所提出的方法显著提高了泛化能力,并支持在单个模型中对包括半透明塑料和金属在内的各种材料的次表面散射和反射。
为了评估方法,团队使用多视角light state capture系统来处理25名被试。每个被试捕获三次;一次不戴眼镜,另两次从43副眼镜中随机选择佩戴。所有的眼镜都是在没有镜片的情况下拍摄。作为预处理,使用可微分神经SDF从多视图图像中单独重建眼镜几何结构。
研究表明,基于这种预先计算的眼镜几何结构精心设计的正则化项显著提高了所提出模型的保真度。他们同时与最先进的生成式眼镜模型进行了比较,并证明了相关表示以及所提出的交互联合建模的有效性。结果进一步证明,这个可变形模型可以通过反向渲染适用于新眼镜,并在新的照明条件下实现重照明。
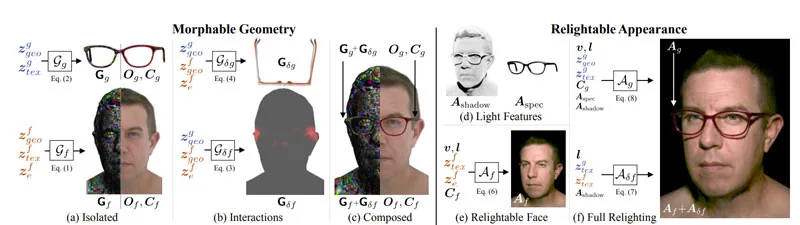
如上图所示,团队提出的方法主要由两部分组成:可变形的几何形状和可重照明的外观。研究人员提出的方法学习单独的latent空间来建模人脸和眼镜的变化,以及它们的几何相互作用,以便模型可以组合在一起。
另外,为了准确地呈现可重照明的外观,计算表示与可重照明面部模型的光交互的特征,以允许联合面部和眼镜重新照明。
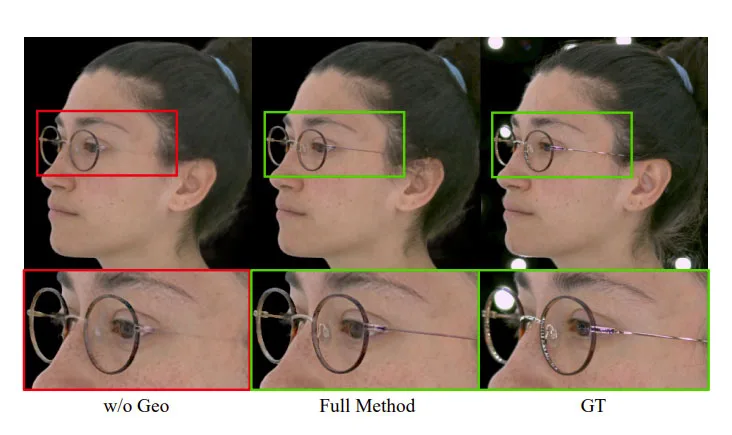
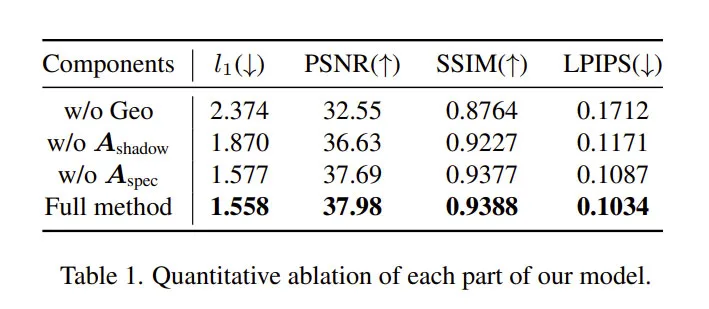
在消融研究中,研究人员首先表明,包括表面法线和分割的几何引导损失,对于实现清晰的眼镜重建至关重要。如图4和表1所示,在不使用几何制导的情况下,模型只使用基于图像的重建和正则化损失进行训练。
然而,它无法重建眼镜的详细几何形状,比如鼻垫。相比之下,具有几何制导的模型实现了更高的几何保真度。
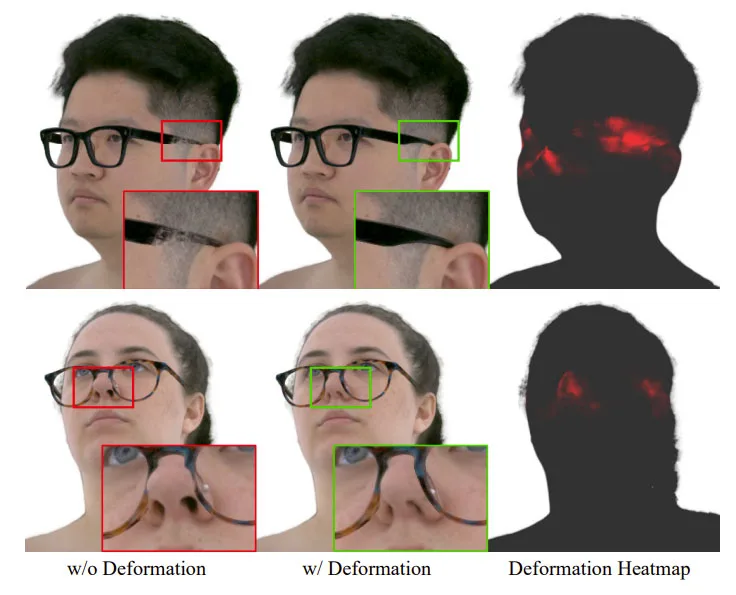
另外,眼镜和人脸在接触点处会发生变形。图5显示,在没有建模这种变形的情况下,镜腿会错误地渲染并穿透头部。通过几何相互作用的建模,团队提出的方法学习并忠实地表示头部和鼻子的变形。

在图6中,受物理学启发的神经重照明功能。团队评估了所提出的镜面和阴影特征对神经重照明的有效性。如图所示,不使用镜面特征的无法重建镜面高光。另外,没有外观交互的模型无法在脸上重建正确的阴影。但完整的方法则可以解决所述问题。
值得一提的是,研究人员同时将他们的方法与最先进的生成式眼镜模型进行了比较。
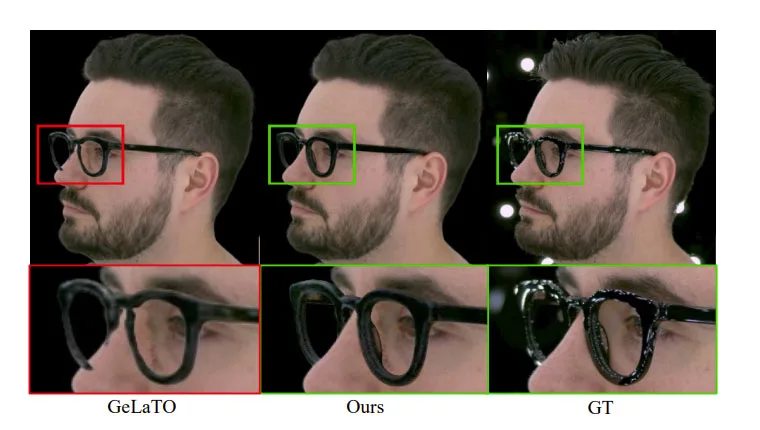
为了进行比较,团队重新实现了GeLaTO,并使用自己的数据集进行训练。由于GeLaTO不支持重照明,所以仅在完全照明的镜架进行比较。图7显示,GeLaTO缺乏几何细节,并且由于几何结构而产生不正确的遮挡边界,而研究人员提出的方法则实现了高保真度结果,并正确处理了遮挡。

表2显示,他们的方法在所有指标上都表现出色。
对于与GIRAFFE的对比。后者提出了一种合成神经辐射场,支持在场景中添加和更改对象。然而,官方实现只支持同一类别中的对象。为了进行公平的比较,团队调整了他们的方法,以支持在多个类别中添加生成式对象。

图8显示,以无监督的方式进行的合成生成式建模依然会导致分辨率有限的次优保真度。基于图像的方法无法保持颜色和视图的一致性。另外,所述方法不能选择特定类型的眼镜。相比之下,团队提出的表示能够在视图和时间上以一致的渲染准确再现眼镜和人脸,并且生成了看似合理的柔和阴影,并准确地模拟了人脸和眼镜之间的光度相互作用。
总的来说,澳大利亚国立大学和Meta的研究人员提出了一种3D可变形和可重照明的眼镜模型MEGANE。它可以在新颖照明下,从任何角度创建眼镜的真实感构图。实验表明,通过利用混合网格体三维生成式模型的神经渲染,现在可以再现几何和光度相互作用。
为了有效地支持眼镜拓扑结构的巨大变化,团队使用了一种结合了表面几何形状和体三维表示的混合表示。与体三维方法不同,所述模型能够自然地保留了眼镜之间的对应关系,因此大大简化了几何结构的显式修改,如镜片插入和镜框变形。
另外,模型在点光源和自然照明下可重照明,支持各种框架材料的高保真渲染,包括在单个可变形模型中的半透明塑料和金属。重要的是,所述方法模拟了全局光传输效应,例如在人脸和眼镜之间投射阴影。另外,这个可变形模型能够通过反向渲染适用于新眼镜。
......(全文 2276 字,剩余 0 字)











