Meta研究提高立体、单目深度估计的时间一致性来改善深度重建

不牺牲空间质量的情况下显著提高了立体和单目深度估计的时间一致性
(映维网Nweon 2023年04月25日)深度重建是计算机视觉中一个长期存在的基本问题。数十年来,最热门的深度估计技术是基于立体匹配或运动结构。但近来最优秀的结果来自于基于学习的方法。随着整体重建质量的提高,焦点已转移到新的领域,如单目估计、边缘质量和时间一致性。
时间一致性对于计算摄影和虚拟现实中的视频应用尤为重要,因为不一致的深度可能会导致令人反感的闪烁和游动伪影。不过,一致的视频深度估计是一个难题,即便是最好的方法都会受到场景内容的不可预测误差和缺陷所影响,尤其是在无纹理和镜面区域。另外,需要在线重建的应用程序则加剧了这一困难。
在名为《Temporally Consistent Online Depth Estimation Using Point-Based Fusion》的论文中,Meta建议使用全局点云来促使在线视频深度估计的时间一致性。他们展示了如何在未来帧未知的情况下处理动态对象和更新静态点云这两个问题。定量和定性结果表明所述方法在不牺牲空间质量的情况下显著提高了立体和单目深度估计的时间一致性。
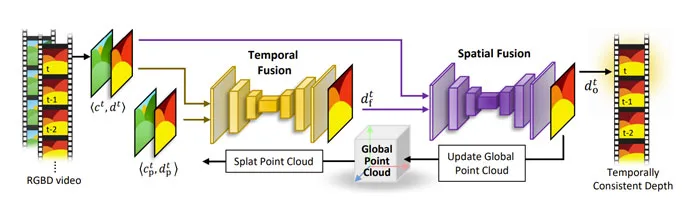
总的来说,Meta主要提出了基于点云的融合,并用于时间一致的视频深度估计。他们提出了一种三阶段方法以促使在线设置的一致性,同时允许更新以提高重建的准确性和处理动态场景。同时,研究人员提出了一种用于动态估计和深度融合的图像空间方法,而所述方法重量轻,运行时开销低。
方法
给定具有已知姿态的RGB图像序列ct,为每个ct,t∈{0,1,2,…}估计深度图dt,使得在时间t可见的所有场景点的几何表示从t-1到t都是准确和一致的。另外,研究人员希望在线解决这个问题;在任何时刻t,未来帧di,i>t都是未知的。
......(全文 1016 字,剩余 399 字)








