Meta专利探索从共享存储器优化AR/VR硬件设备

多存储体、多端口分布式共享存储器系统
(映维网Nweon 2022年12月19日)Meta正在从各个方面优化AR/VR硬件设备。在名为“Artificial reality system having multi-bank, multi-port distributed shared memory”的专利申请中,这家公司介绍了使用一个或多个多存储体、多端口分布式共享存储器系统实现的人造现实系统。
所述的共享存储器系统可以实现为一个或多个集成电路和/或SoC的一部分。在一个实施例中,所描述的共享存储器系统可以在逻辑上视为单个实体存储体空间,但在物理上可以具有多个存储体组。通过将特定存储体与某些其他组件或子系统相关联,可以减少对同一存储体的并发访问的可能性,并且因此减少对锁定的需要。另外,有限的路径长度可以帮助限制功耗,并且可以减少存储体延迟。团队表示,这种变化的延迟可以为特定应用提供调整SoC性能的机会。
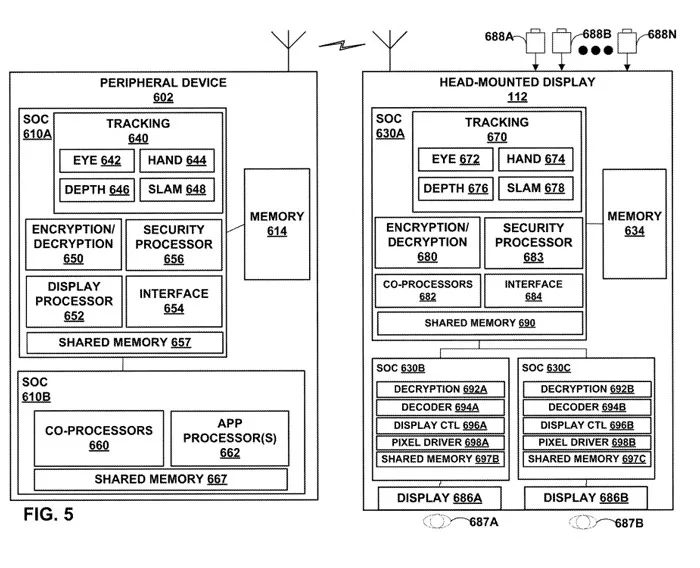
图5示出了头显和外设的分布式架构框图。头显可以构造和配置为实现多个人造现实应用和协作场景渲染的并发执行。
通常,图5中所示的SoC表示以分布式架构布置的专用集成电路的集合,其中每个SoC集成电路包括配置为为人造现实应用提供操作环境的各种专用功能子系统和/或模块。图5仅仅是SoC集成电路的一个示例性布置。用于多设备人工现实系统的分布式架构可以包括SoC集成电路的任何集合和/或布置。
在这个示例中,头显112的SoC 630A包括功能块、子系统和/或模块,包括追踪模块670、加密/解密模块680、协处理器682、安全处理器683、接口模块684和共享存储器690,和/或同时定位和映射(SLAM)678、以及共享存储器657
共享存储器657可以实现为多存储体、多端口分布式延迟共享存储器系统。
在一个实施例中,SoC 610A和SoC 601B中的每一个可以分别包括共享存储器657和共享存储器667。共享存储器657和667中的每一个可以实现多存储体、多端口分布式共享存储器系统。类似地,SoC 630A、630B和630C中的每一个都可以包括共享存储器,并实现为多存储体、多端口分布式共享存储器系统。
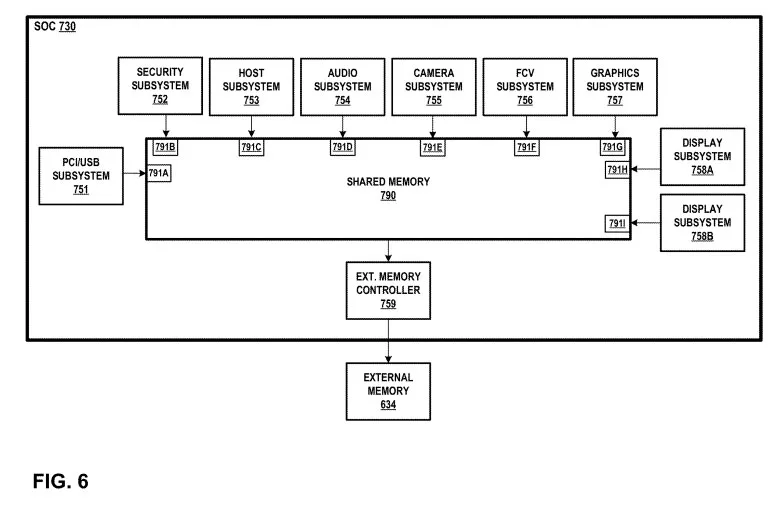
图6是示出了一个SoC框图,其包括可由多个组件、子系统和/或设备访问的示例共享存储器。图6的SoC 730可以对应于图5的SoC中的一个或多个,例如头显 112的SoC 630A。图6示出了可由多个子系统或组件访问的共享存储器790,以及显示子系统758B。
图6的示例中的SoC 730可以对应于SoC 630A的示例,SoC 730可以包括在头显 112内,并且可以执行与图像捕获、音频捕获、眼睛、手和/或深度追踪、姿势确定、输入检测、加密和/或描述以及内容生成和/或显示相关的功能。
在图6的示例中,每个示出的子系统可以将数据存储到共享存储器790,并从共享内存790中检索数据,其中共享存储790在实现SOC 730的集成电路的内部,并且用作多存储体、多端口分布式共享存储系统。
从每个子系统的角度来看,共享存储器790在逻辑上可以表现为单个实体或单个存储体设备,但同时可以包括多个存储体组(图6中未示出),每个存储体组在SoC 730集成电路内部并且可由任何子系统访问。
在一个实施例中,共享存储器790中包括的每个存储体(图6中未具体示出的存储体)可由子系统通过SoC 730的集成电路内的共享存储器7900所呈现的端口或接口来访问,以经由内部网络向共享存储器790/从共享存储器790读取数据。
在图6的示例中,PCI/USB子系统751可以通过端口791A访问共享存储器790。类似地,安全子系统752可以通过端口792B访问共享存储器791;摄像头子系统755可以通过端口791E访问共享存储器790;FCV子系统756可以通过端口79F访问共享存储器791‘图形子系统757可以通过接口791G访问共享存储器792等等。
在一个实施例中,图6中所示的与给定子系统相关联的每个端口都可以专用于子系统,使得子系统对存储体的所有访问都通过单个端口进行。例如,PCI/USB子系统751可以通过端口791A访问共享存储器790中包括的任何存储体。相应地,安全子系统752可以通过端口791B访问包括在共享存储器790内的任何存储体。
图6的系统还可以包括外部存储体控制器759,其允许访问附加存储体,例如外部存储体634(例如,但通常具有比包括在共享存储器790内的存储体更大的延迟。
在一个实施例中,多个存储体(或每个存储体)可以通过低延迟连接来访问,并且可以由SoC 730内的子系统同时和/或并发地访问。这样的能力可以通过包括在共享存储器790内的网络来实现。
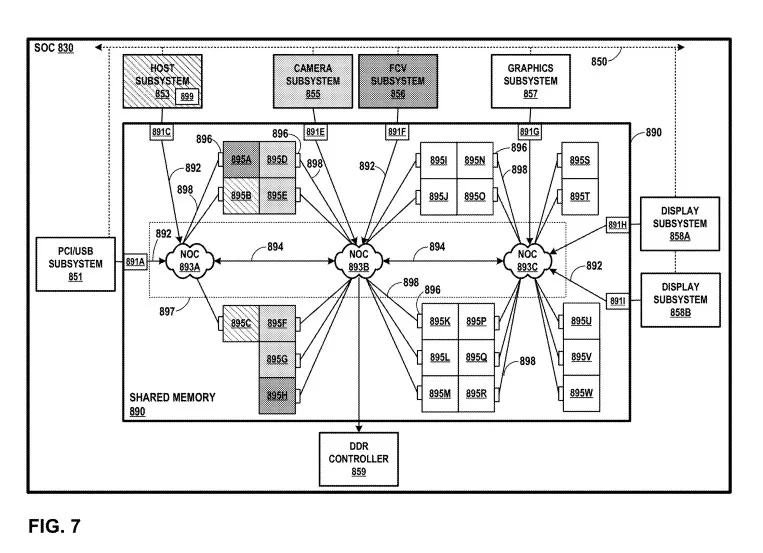
图7示出了具有多个存储体和多个端口的共享存储器系统的示例SoC框图。图示的子系统中的每一个子系统可以通过总线850进行通信,并用于各种目的,包括在共享存储器890内分配内存。主机子系统853可以包括内存管理模块899。共享存储器8900包括网络897,网络897允许访问多个存储体中的每个存储体。
在一个实施例中,存储体组895中的每一个可以具有相同的设计或统一的设计,潜在地在性能和密度方面以及在延迟和功耗方面实现规模效应。例如,多个存储体895中的每一个的统一设计可以提供优化每一个这样的存储体的尺寸的机会,最终使得更多的存储体包括在给定尺寸的芯片中。
每个存储体895可以配置有功耗特征,例如自动(或根据命令)转换到低功率或睡眠模式的能力。在一个示例中,每个存储体895可以在共享存储器890内独立地操作,并且可以独立地能够确定何时转换到低功率模式。
在一个实施例中,存储体组895中的每一个可以具有1兆字节量级的大小。因此,在图7的SoC 830的具体示例中,共享存储器890可以具有大约23兆字节的容量。这种大小的存储体可以是在集成电路上实现的相对大量的存储体。因此,SoC 830可以来抵消集成到集成电路中的大量存储体的潜在负面影响,并可用于减少存储体延迟、提供变化的延迟分布、提高效率、实现低功耗以及提供其他技术方面有利的属性。
在图7的示例中,所示的每个子系统通过端口891之一访问存储体895,特别是,在图7的示例中,PCI/USB子系统851通过端口891A访问存储体895,FCV子系统856通过端口891F访问存储体895,图形子系统857通过端口89G访问存储体895,显示子系统858A通过端口891H访问存储体内895,而显示子系统8.58B通过端口8911访问存储中895。
在图7中,每个端口891示为通过连接892中的一个连接到另一个交换机893。例如,端口891A示为经由连接892连接到交换机893A。类似地,端口891C示为经过不同的连接892与交换机893A连接。
SoC 830的每个子系统对存储体895的访问可以通过网络897进行,网络897将每个子系统的专用端口891连接到每个存储体891,和交换机893C以及端口891、交换机893和存储体895之间的连接(892、894和898)。
交换机893可以启用共享存储器890内的多个组件之间的连接,同时限制共享存储器8900内的物理连接的数量。多个交换机893的适当使用可以减少并行连接的数量,并且可以使共享存储器890内的多个组件能够将相同的连接用于复用业务。
在一个示例中,每个交换机893用作具有多个不同仲裁器的交叉开关。开关893之一内的每个仲裁器确定涉及存储体895之一的存储体操作是否需要执行仲裁。例如在图7中,交换机893C可以包括11个不同的仲裁器,因为交换机893C具有11个输出端口。在11个输出端口中,10个通向存储体895之一,另一个输出端口通向交换机893B。
在图7中,开关893中的每一个可以实现对多个存储体895的独立和并发访问,开关893C能够使请求子系统独立地和同时地访问存储体895N和895S中的每一个。如果交换机893C具有这样的能力,则可能不需要对这样的存储体访问执行仲裁,并且请求子系统可以独立地和并发地访问存储体组895N和895S中的每一个。
图7的SoC 830可以是图6的SoC 730的替代或示例实现。类似地,图7的SoC 830可以对应于图5的一个或多个SoC,例如头显 112的SoC 630A。
使用外部存储体不仅在延迟方面而且在功耗方面可能成本昂贵,所以共享存储器890可以实现为SoC 830的一部分,并且可以以实现低延迟、并发访问和低功耗特征的方式来设计和/或实现。
例如,在图7中,多个交换机893用于在存储体895之间路由存储体业务。尽管在特定设计中可以使用单个交换机或NOC,但如果NOC路由的存储体业务量大,则这样的交换机或NOB可能成为拥塞点。另外,单个交换机或NOC可能需要较大的尺寸,而较大的NOC往往会消耗大量的电力。
因此,以图7所示的方式使用多个NOC可能是有利的。例如,使用多个交换机893使得交换机893中的每一个都能够在多个交换机892上分配存储体业务,这不仅减少了任何给定交换机893处的拥塞,而且这样的系统中的交换机893的每一个中的每个都倾向于消耗更少的功率。
在一个实施例中,对多个存储体895的访问可以是并发进行,而不需要存储体业务穿越任何公共点。例如,PCI/USB子系统851可以通过端口891A访问共享存储器890来访问存储体组895A。类似地,显示子系统858B可以通过端口8911访问共享存储器890来访问存储体组895N。
在这样的示例中,到存储体组895A和存储体组895N中的每一个的存储体业务不需要经过任何公共点,因此存储体组896A和存储体组1895N可以由PCI/USB子系统851和显示子系统858B同时访问。
并发访问反过来可以提供显著的带宽增强,这是与使用单个NOC执行对存储体的共享访问的系统相比的一个优势。例如,如果四个不同的子系统同时访问四个存储体895,则共享存储器890的有效存储体速度或带宽可以比单个存储体890的访问速度快四倍。
在一个实施例中,连接892、路径894和连接898的物理长度可能对给定端口891和给定存储体895之间的延迟产生影响,因为这些连接或路径可以在集成电路上延伸的距离通常存在电限制。如果连接或路径太长,可能需要重新放大信号,以便信号在沿着连接或路径到达目的地时保持稳定。在这种情况下,这种再放大可能需要额外的时钟周期,从而增加延迟。
因此,有限的路径长度可以帮助限制功耗,并且可以减少存储体延迟。
因为与从端口891H到存储体组895A的物理距离相比,从端口891A到存储体组1895A的物理距离(连接892和898的长度)可能相对较短,从端口891A到存储体895A的等待时间可以减少。
这种分布式延迟设计同时具有功耗优势。例如,SoC 830可以通过限制到存储体895的业务所经过的跳数、通过限制到存储体组895的公共或典型存储体业务所行进的连接的长度、以及通过限制SoC 830内的连接、导线和/或路径的长度来节省电能,因为使用单个NOC实现共享存储器可能需要单个NOC消耗大量功率。作为实现分布式延迟设计的设计考虑的结果,SoC 830的功耗属性因此可以得到改善。
在一个实施例中,每个存储体895同时可以配置有额外的功耗特征,例如自动(或根据命令)转换到低功率或睡眠模式的能力。例如,每个存储体895独立地在SoC 830操作,并且独立地能够确定何时转换到低功率模式。可以基于自先前访问该存储体组89以来已经过了多少时间和/或基于倾向于访问给定存储体组899的子系统的访问模式,存储体组895中的每一个可以确定是否转换到休眠模式或低功率模式,并通过评估共享存储器890的这种访问模式和/或使用模式以及学习用于进行这种转换的适当或最佳阈值。
SoC 830同时可以通过基于每个这样的子系统的预期使用模式来调整延迟来设计。例如,可以在设计时知道数据预期如何在SoC 830内流动。利用相关知识,可以做出有助于减少公共存储体操作的延迟、实现并行存储体操作以及减少SoC 830的总体功耗需求的设计选择,交换机893的数量和物理布置,以及通常由交换机893和连接892、路径894和连接898组成的网络拓扑。
对于通用SoC,在设计时不知道预期使用情况,这种设计选择不可能或不可取。但如果在设计时已知有关预期用例的重要信息,则可以做出对内存延迟和电源效率有重大影响的设计选择。这样的设计选择同样可以在设计后期进行,使得能够在制造对应于SoC 830的集成电路之前部署与预期使用模式相关的定制并利用预期使用模式。
因此,一个或多个存储体895可以这样的方式布置在SoC 830上,以实现特定子系统的高效访问。
相关专利:Meta Patent | Artificial reality system having multi-bank, multi-port distributed shared memory
名为“Artificial reality system having multi-bank, multi-port distributed shared memory”的Meta专利申请最初在2022年8月提交,并在日前由美国专利商标局公布。
......(全文 4006 字,剩余 0 字)








