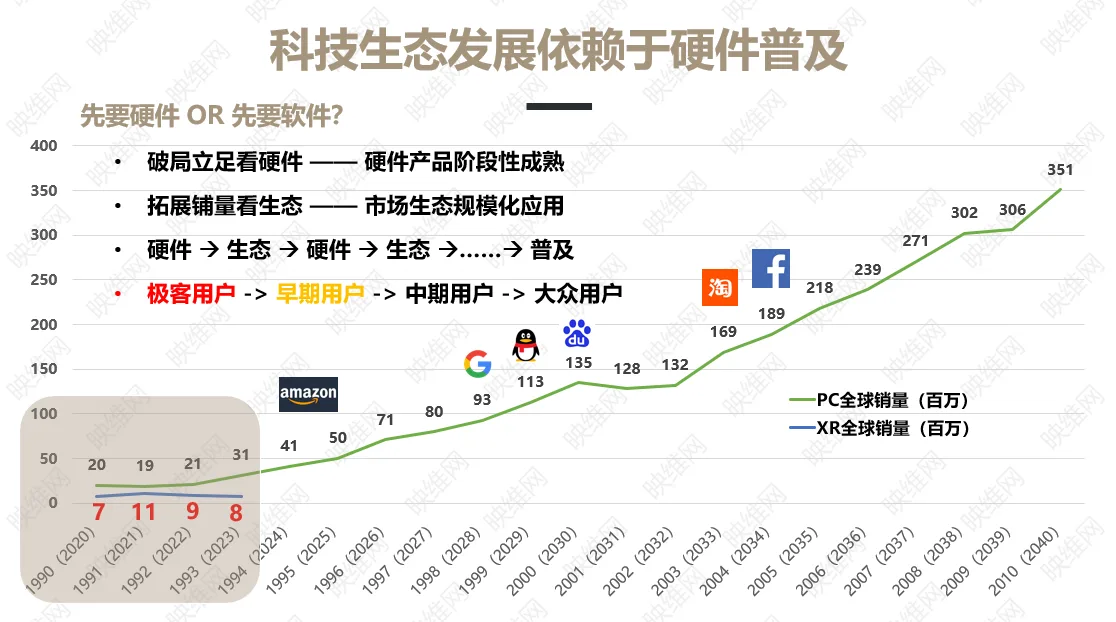
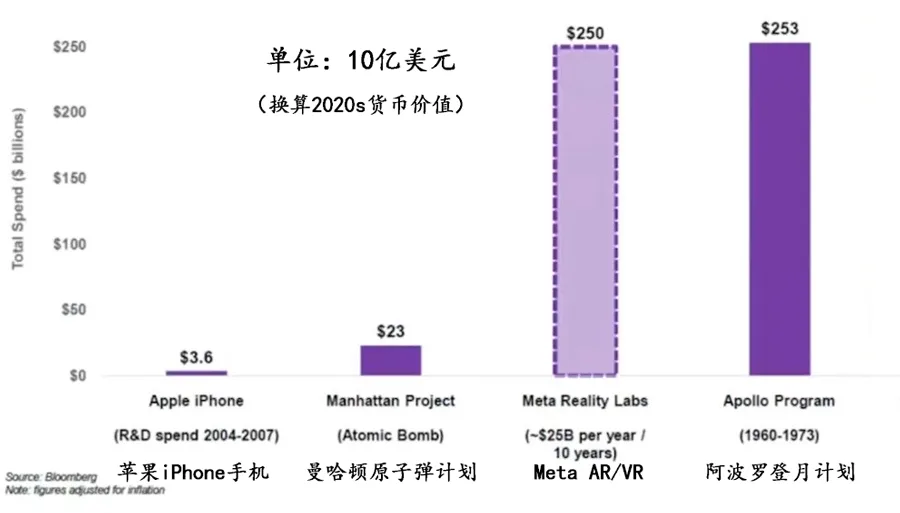
斯坦福大学等团队提出生成人体可编辑辐射场3D感知GAN框架

美国斯坦福大学,荷兰代尔夫特理工大学,以及加拿大多伦多大学
(映维网Nweon 2022年12月06日)使用非结构化单视图图像的大规模数据集对3D感知生成对抗网络(GAN)进行无监督学习是一个新兴的研究领域。最近,业界证明这种3D GAN能够实现照片真实感和多视图一致的人脸辐射场生成代。
但所述方法尚未证明对身体有效。一个原因是,由于身体的关节铰接与面部相比多样性明显更高,所以学习身体姿势分布更具挑战性。然而,照片真实感人类的生成3D模型在视觉效果、计算机视觉、虚拟现实/增强现实等广泛应用中具有重要的实用价值。在相关场景中,生成的人体必须可编辑,从而支持交互式应用程序。
现有的3D GAN并不一定支持。尽管线性混合蒙皮的变体已可用于阐明单个场景的辐射场,但尚不清楚如何将这种变形方法有效地应用于生成模型。
在名为《Generative Neural Articulated Radiance Fields》的研究中,由美国斯坦福大学,荷兰代尔夫特理工大学,以及加拿大多伦多大学组成的团队提出了一个生成神经铰接辐射场GNARF。
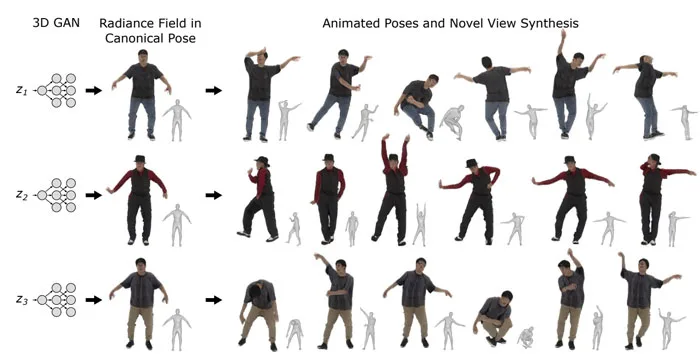
研究人员为针对上挑战提出了自己解决方案。首先,他们演示了在包含单视图图像的数据集上以无监督方式训练的GAN生成高质量3D人体。为此,团队采用了对于训练和渲染辐射场非常有效,同时与传统的基于2D CNN的生成器兼容的三平面特征表示。
其次,作为GAN训练过程的一环,团队通过引入显式辐射场变形步骤来解决生成辐射场的可编辑性。所述步骤确保生成器以标准身体姿势合成人的辐射场,然后根据训练数据的身体姿势分布显式扭曲辐射场。实验表明,这种新方法可以生成高质量、可编辑、多视图一致的人体,并且可以应用于编辑人脸,从而提高了现有生成模型的可控性。
......(全文 3263 字,剩余 2651 字)