Meta介绍构建弱监督语义神经域方法,从无标记数据中学习3D语义场景表示

从很少或没有标记的数据中学习3D语义场景表示
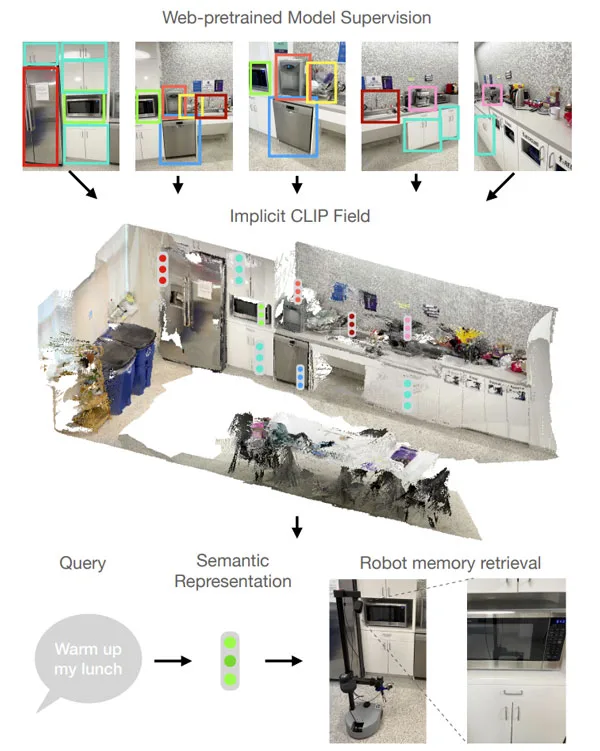
(映维网Nweon 2022年11月01日)用于隐式表示3D场景的模型显示了作为计算机视觉工具的巨大前景。神经辐射场(NeRFs)和更一般的隐式神经表示可作为时空状态的可微分数据库。另外有项研究表明,网络规模的弱监督视觉语言模型可以捕获强大的语义抽象。
这已证明对一系列用例非常有用,包括对象理解。然而,相关应用受到以下事实的限制:经过训练的表示假定单个2D图像作为输入。如何最好地使用模型来实现视觉语言模型所提供的所有优点的3D推理一直是一个悬而未决的问题。
在名为中《CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory》的论文中,纽约大学和Meta旗下FAIR Labs介绍了一种构建弱监督语义神经域的方法CLIP-Fields,它可以从很少或没有标记的数据中学习3D语义场景表示。需要注意的是,尽管所述方法主要描写应用于机器人,但相关的技术理论上可用于XR。
......(全文 2075 字,剩余 1744 字)








