挑战相机、人物同时移动,谷歌实现高质量3D深度信息重建,避免直接3D三角测量

查看引用和消息源请点击:映维网
用于深度预测的深度学习方法
(映维网 2019年05月28日)人类视觉系统非常强大,它能够根据二维投影理解我们的三维世界。即使是在具有多个移动对象的复杂环境中,人类都能够解释对象的几何形状和深度排序。长期以来,计算机视觉一直在研究如何通过从二维图像数据来计算重建场景几何,从而复刻人类的这项独特能力。但在大多数情况下,计算机视觉系统都难以实现稳定的重建。
当摄像头和场景对象都能自由移动时,这将变得特别具有挑战性。因为它会混淆基于三角测量的传统三维重建算法:它假设可以同时从至少两个不同的视点感知相同的对象。满足这个假设需要一个多摄像头阵列(如谷歌Jump);或者需要场景保持静止,并且只有单个摄像头移动。因此,大多数现有方法要么是过滤掉移动对象(将它们指定为“零”深度值),要么忽略它们(导致不正确的深度值)。
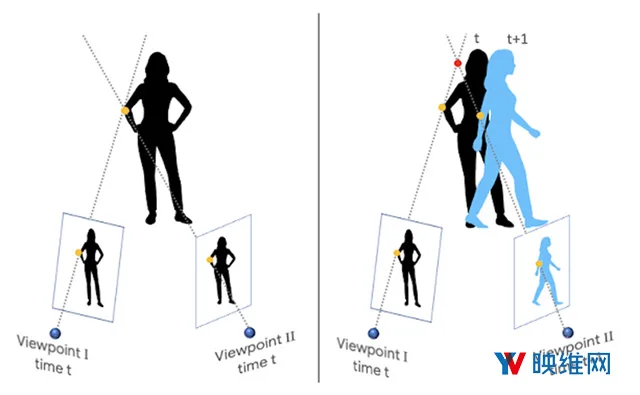
在《Learning the Depths of Moving People by Watching Frozen People》这篇论文中,谷歌的研究团队应用了基于深度学习的解决方案。所述方法可以根据摄像头和对象都能自由移动的普通视频生成深度图,并且通过关于人体姿势与形状的机器学习来避免直接的3D三角测量。尽管业界近来已经开始利用机器学习进行深度预测,但谷歌表示,他们的研究是首个为摄像头和对象自由移动的情况而开发的深度学习方案。对于这项研究,谷歌主要专注于人类,因为它们适用于增强现实和3D视频效果。

1. 获取训练数据
谷歌采用了监督式深度预测模型训练方案,这需要通过移动摄像头来捕获自然场景视频,以及精确的深度图。关键的问题是,从哪里获取这类数据。合成数据需要对各种场景和自然人类行为进行逼真的建模和渲染,这非常具有挑战性。另外,基于这种数据进行训练的模型可能难以推广到真实场景。另一种潜在的方法是利用RGBD传感器(如微软Kinect)来记录真实场景,但深度传感器通常仅限于室内环境,而且它们存在自己的三维重建挑战。
谷歌选择了利用现有的数据源:YouTube视频。YouTube存在大量的假人挑战:每个人摆出特定的造型,然后不眨眼、不出声、一动不动,就像玻璃橱窗里的假人模特。因为整个场景都是静止(只有摄像头在移动,所以基于三角测量的方法行之有效,而我们可以获取包含真人在内的整个场景的精确深度图。我们采集了大约2000的视频,它们涵盖了各种逼真的场景,而且人们自然地以不同的群体配置摆造型。
......(全文 1565 字,剩余 712 字)