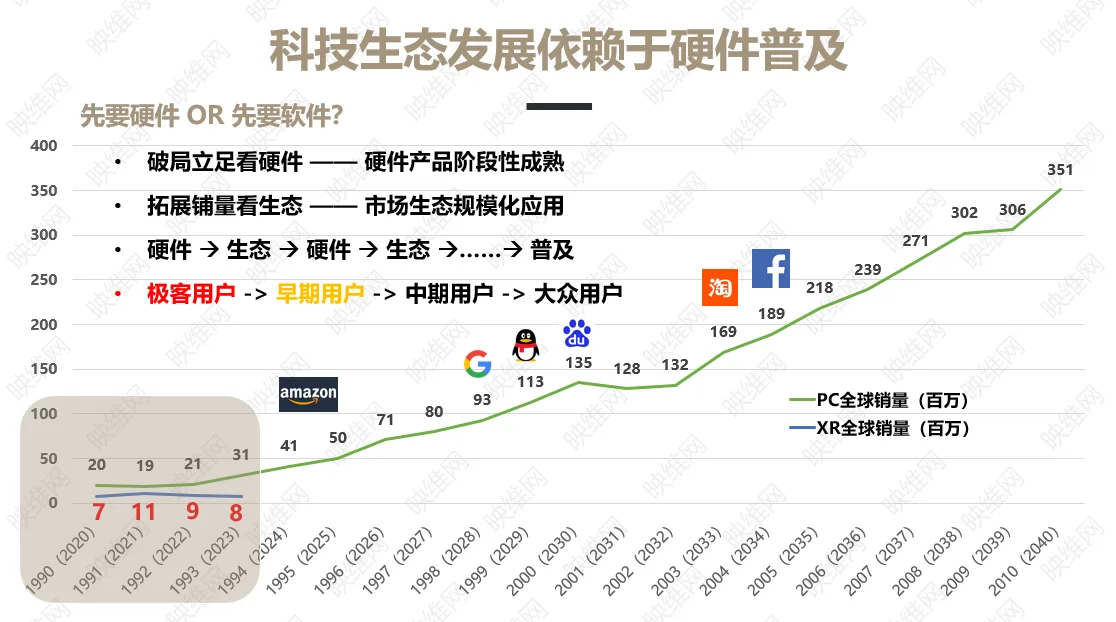
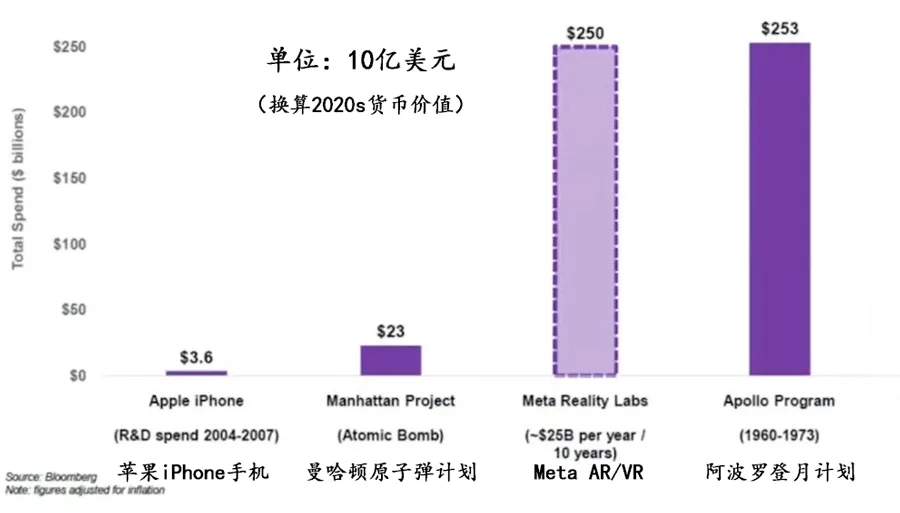
无需眼动追踪硬件,新方法用头部运动和视觉画面预测用户注视方向

无需专用眼动追踪硬件的注视预测方法
(映维网Nweon 2026年04月20日)注视预测在VR中发挥着关键作用,它能够减少传感器引起的延迟,并支持诸如注视点渲染等计算密集型技术。在一项研究中,来自希腊和塞浦路斯的研究团队提出了一种新颖的注视预测框架,将头戴式显示器的运动信号与视频帧中提取的视觉显著性线索相结合,无需眼动追踪设备就能预测用户注视方向。
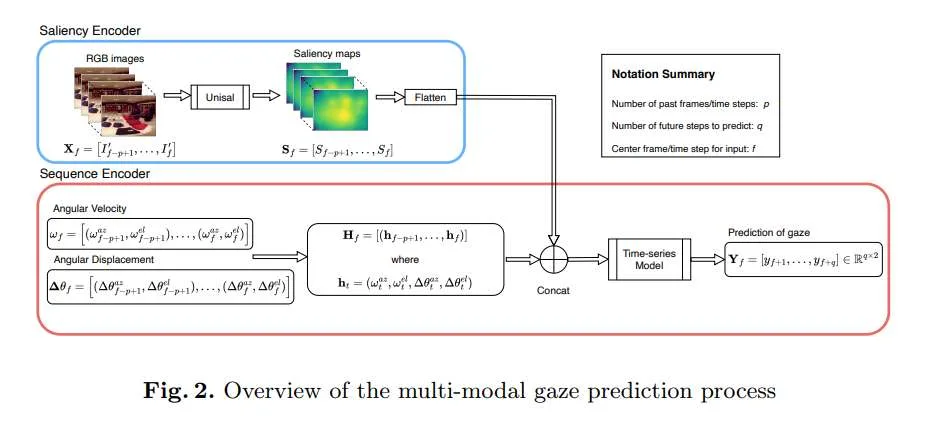
对于VR应用,提前预判用户的注视方向有助于降低画面延迟、提升渲染效率,并改善交互体验。然而,有的VR头显并未配备眼动追踪功能,或出于隐私考虑限制了眼动数据的获取。针对这一问题,来自希腊和塞浦路斯的研究团队提出了一种无需专用眼动追踪硬件的注视预测方法。
所述解决方案仅利用头戴式显示器的运动信号(如头部转动的角速度、角位移)以及VR画面中的视觉显著性信息(即人眼可能关注的重点区域),即可预测用户在未来约三分之一秒到一秒内的注视位置。
......(全文 740 字,剩余 379 字)
 请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
映维网会员可直接登入网站阅读
PICO员工可联系映维网免费获取权限